 Web feed
Web feed OPML
OPMLHow can I identify an error "reading CGI reply" when running a Perl Mail::Mailer script under NGINX
Perl questions on StackOverflowPublished by Dave Everitt on Friday 18 July 2025 19:43
After updating CPAN and "Mail::Mailer" and installing FCGI I’m getting an error (see below):
#!/usr/bin/perl
use strict;
use CGI::Carp qw(fatalsToBrowser);
use Mail::Mailer;
my $to = "address1\@domain.com";
my $from = "address2\@domain.com";
my $subject = "Hello from OVHc CEM";
my $body = "Hello from OVHc";
my $mailer = Mail::Mailer->new();
$mailer->open({ From => $from,
To => $to,
Subject => $subject,
})
or die "Can't open: $!\n";
print $mailer $body;
$mailer->close();
The error: "An error occurred while reading CGI reply (no response received)".
NGINX error log shows:
sendmail.cgi: Execu" while reading response header from upstream, client: IP_ADDRESS, server: secure.DOMAIN.uk, request: "GET /cgi-bin/sendmail.cgi HTTP/1.1", upstream: "fastcgi://unix:/var/run/fcgiwrap.socket:", host: "secure.DOMAIN.uk"
[error] 7371#7371: *1077691 FastCGI sent in stderr: "tion of /home/USER/cgi-bin/sendmail.cgi aborted due to compilation errors" while reading response header from upstream, client: 81.96.251.80, server: secure.DOMAIN.uk, request: "GET /cgi-bin/sendmail.cgi HTTP/1.1", upstream: "fastcgi://unix:/var/run/fcgiwrap.socket:", host: "secure.DOMAIN.uk"
Might I be better off using Mail::Sendmail?
Sadly, my Perl Monk friend is no longer with us, so I’m wading through this as a Perl novice.
perlintro: fix minor grammar mistake
Perl commits on GitHubPublished by akarelas on Friday 18 July 2025 12:37
perlintro: fix minor grammar mistake
Dancer 2.0.ohh-myyy ~ Jason Crome ~ TPRC 2025 - YouTube
r/perlPublished by /u/briandfoy on Friday 18 July 2025 11:31
 | submitted by /u/briandfoy [link] [comments] |
Perl: IPC::Run escaping problems with special characters, commands not working
Perl questions on StackOverflowPublished by user31061291 on Friday 18 July 2025 08:24
I am having problems running commands using IPC::run with special characters, in my current case ' and *
The used commands:
apt-get -y --allow-unauthenticated -o Dpkg::lock::timeout=0 install /tmp/archive-keyring*.deb
(the file /tmp/archive-keyring_2022.04.01~tux_all.deb exists)
and
dpkg-query -f '${db:Status-Abbrev} ${Package} ${Version}\n' -W 'archive-keyring'
work without problems when used on a CLI with sudo. Of course this script has to be started as sudo as well. If it helps, I am using an Ubuntu system.
The module I am using is libipc-run-perl version 20231003.0-1
Here the example script:
#!/usr/bin/perl -w
use strict qw(vars subs);
use warnings;
use IPC::Run qw( run timeout );
use Data::Dumper;
# for debugging
$ENV{IPCRUNDEBUG} = 'data';
sub startProgram {
my ($subOutput, $subErrors, $subTimeout, $subReturnValue, @subCommand) = @_;
# for debug
print Dumper(@subCommand);
my $runExitCode = q{};
eval {
# undef has to be \undef !!
$runExitCode = run \@subCommand, \undef, $subOutput, $subErrors, timeout ( $subTimeout, exception=>'timeout' );
};
if ($@ =~ /timeout/) {
$subReturnValue = exitCode();
print "Timed out...\n";
} else {
$subReturnValue = exitCode();
print "Completed task without timeout\n";
}
print "output: >$$subOutput<\n".
"errors: >$$subErrors<\n".
"return value: >$subReturnValue<\n".
"run exit code: >$runExitCode<\n\n";
return ($runExitCode);
}
sub exitCode {
return ($?>>8);
}
my $output = q{};
my $errors = q{};
my $timeout = 5;
my $retVal = q{};
# does not work
# problem is: *
# actual command on cmdline:
# apt-get -y --allow-unauthenticated -o Dpkg::lock::timeout=0 install /tmp/archive-keyring*.deb
my @command1 = (
'apt-get',
'-y',
'--allow-unauthenticated',
'-o',
'Dpkg::lock::timeout=0',
'install',
'/tmp/archive-keyring*.deb');
startProgram(\$output, \$errors, $timeout, \$retVal, @command1);
# does not work
my @command2 = (
'apt-get',
'-y',
'--allow-unauthenticated',
'-o',
'Dpkg::lock::timeout=0',
'install',
'/tmp/archive-keyring\*.deb');
startProgram(\$output, \$errors, $timeout, \$retVal, @command2);
# does not work
my $fileName = q{/tmp/archive-keyring*.deb};
my @command3 = (
'apt-get',
'-y',
'--allow-unauthenticated',
'-o',
'Dpkg::lock::timeout=0',
'install',
$fileName);
startProgram(\$output, \$errors, $timeout, \$retVal, @command3);
# this works !! but I have to use * for different reasons
# I am using here the full filename of the package
my @command4 = (
'apt-get',
'-y',
'--allow-unauthenticated',
'-o',
'Dpkg::lock::timeout=0',
'install',
'/tmp/archive-keyring_2022.04.01~tux_all.deb');
startProgram(\$output, \$errors, $timeout, \$retVal, @command4);
# Another command I need and is not working:
# dpkg-query -f '${db:Status-Abbrev} ${Package} ${Version}\n' -W 'archive-keyring'
# here the problem seems to be: '
# IPC::run seems to convert ' into ''
# does not work
my @command5 = (
'dpkg-query',
'-f',
'\'${db:Status-Abbrev} ${Package} ${Version}\n\'',
'-W',
'\'archive-keyring\'');
startProgram(\$output, \$errors, $timeout, \$retVal, @command5);
# does not work
my @command6 = (
"dpkg-query",
"-f",
"'\${db:Status-Abbrev} \${Package} \${Version}\n'",
"-W",
"'archive-keyring'");
startProgram(\$output, \$errors, $timeout, \$retVal, @command6);
# does not work
my $package = 'archive-keyring';
my @command7 = (
"dpkg-query",
"-f",
"'\${db:Status-Abbrev} \${Package} \${Version}\n'",
"-W",
$package);
startProgram(\$output, \$errors, $timeout, \$retVal, @command7);
# does not work
# same as before but completely separated as array
my @command8 = (
'dpkg-query',
'-f',
'\'${db:Status-Abbrev}',
'${Package}',
'${Version}\n\'',
'-W',
'\'archive-keyring\'');
startProgram(\$output, \$errors, $timeout, \$retVal, @command8);
# does not work
my @command9 = (q{dpkg-query}, q{-f}, q{'${db:Status-Abbrev} ${Package} ${Version}\n'}, q{-W}, q{'archive-keyring'});
startProgram(\$output, \$errors, $timeout, \$retVal, @command9);
exit (0);
Somehow I am having problems escaping the characters * and '. It seems like IPC::run itself is escaping the characters as well rendering the commands useless.
What am I doing wrong?
How do I escape correctly?
Some of the debug info I get are:
execing /usr/bin/apt-get -y --allow-unauthenticated -o Dpkg::lock::timeout=0 install /tmp/archive-keyring*.deb
errors: >E: Unsupported file /tmp/archive-keyring*.deb given on commandline
execing /usr/bin/dpkg-query -f ''${db:Status-Abbrev} ${Package} ${Version}\n'' -W 'archive-keyring'
errors: >dpkg-query: no packages found matching 'archive-keyring'
IPC::Run 0001 [#6(14085) dpkg-query]: execing /usr/bin/dpkg-query -f ''${db:Status-Abbrev} ${Package} ${Version}
IPC::Run 0001 [#6(14085) dpkg-query]: '' -W 'archive-keyring'
errors: >dpkg-query: no packages found matching 'archive-keyring'
IPC::Run 0001 [#7(14086) dpkg-query]: execing /usr/bin/dpkg-query -f ''${db:Status-Abbrev} ${Package} ${Version}
IPC::Run 0001 [#7(14086) dpkg-query]: '' -W archive-keyring
errors: >dpkg-query: no packages found matching archive-keyring
execing /usr/bin/dpkg-query -f '${db:Status-Abbrev} ${Package} ${Version}\n' -W 'archive-keyring'
errors: >dpkg-query: error: need an action option
As I said, the commands work perfectly when entered into a terminal.
mg.c: Fix misspelling in comment
Perl commits on GitHubPublished by khwilliamson on Thursday 17 July 2025 18:01
mg.c: Fix misspelling in comment
perlapi: Fix misspelling
Perl commits on GitHubPublished by khwilliamson on Thursday 17 July 2025 18:01
perlapi: Fix misspelling
perlintern: Document sv_dup(_inc)?
Perl commits on GitHubPublished by khwilliamson on Thursday 17 July 2025 15:23
perlintern: Document sv_dup(_inc)? This moves these from perlapi to perlintern, adding documentation.
Classes in Corinna and Camelia ~ Matthew Stuckwisch - TPRC 2025 - YouTube
r/perlPublished by /u/briandfoy on Thursday 17 July 2025 11:31
 | submitted by /u/briandfoy [link] [comments] |
CPANTesters Update ~ D Ruth Holloway
The Perl and Raku Conference YouTube channelPublished by The Perl and Raku Conference - Greenville, SC 2025 on Thursday 17 July 2025 11:09
Raku 6.e ~ Will Coleda ~ TPRC 2025 ~ Lightning Talk
The Perl and Raku Conference YouTube channelPublished by The Perl and Raku Conference - Greenville, SC 2025 on Thursday 17 July 2025 08:15
What is Unicode? ~ Karl Williamson ~ TPRC 2025 ~
The Perl and Raku Conference YouTube channelPublished by The Perl and Raku Conference - Greenville, SC 2025 on Thursday 17 July 2025 04:04
cpan/Socket - Update to version 2.040
Perl commits on GitHubPublished by leonerd on Thursday 17 July 2025 00:31
cpan/Socket - Update to version 2.040
2.040 2025-07-16
[BUGFIXES]
* Fix test skip count for INET6 sockaddr tests (RT168005)
(no code change other than unit tests)
2.039 2025-06-25
[BUGFIXES]
* Make sure to invoke GETMAGIC on arguments to `pack_sockaddr_in` and
`pack_sockaddr_in6` (RT166524)
CLI Tool: Highlight and colorize text on your terminal for easier readabililty
r/perlPublished by /u/scottchiefbaker on Wednesday 16 July 2025 21:46
I'm working on polishing up some code on a Perl CLI util that I use frequently. Often I'll find myself tailing log files and wanting to colorize patterns to make reading lots of data at a glance easier.
Highlight to the rescue.
Very simple app to make your CLI more colorful. Please take a look and provide some feedback.
[link] [comments]
Yet Another Program on Closures ~ Steven Lembark ~ TPRC 2025 - YouTube
r/perlPublished by /u/briandfoy on Wednesday 16 July 2025 11:31
 | submitted by /u/briandfoy [link] [comments] |
Help Us Improve Perl 5 ~ Karl Williamson ~ TPRC 2025 ~ Lightning Talk
The Perl and Raku Conference YouTube channelPublished by The Perl and Raku Conference - Greenville, SC 2025 on Wednesday 16 July 2025 09:11
Guide: Pocket PERL During the Upcoming Token Shower
Perl on MediumPublished by Perlin on Wednesday 16 July 2025 08:59
Reconstructing My Blog from 1997 to 2018 Using React and Publishing It on a Custom Domain
Perl on MediumPublished by Keiko | kkoisland on Wednesday 16 July 2025 04:38
Introduction
Test2::UI Howto ~ Andy Baugh ~ TPRC 2025
The Perl and Raku Conference YouTube channelPublished by The Perl and Raku Conference - Greenville, SC 2025 on Tuesday 15 July 2025 19:16
The Call for Papers for the 2025 Perl Advent Calendar is now open.
[link] [comments]
Installing par-packer under Cygwin: Perl version mismatch woes
Perl questions on StackOverflowPublished by neilw on Monday 14 July 2025 23:52
I am trying to get par-packer running under Cygwin and having problems with Perl version mismatch. After installing and trying to run, I get this error:
bin > pp -o ehive_decode.exe myscript.pl
Perl (/usr/bin/perl) version (5.40.2) doesn't match the version (5.40.0) that PAR::Packer was built with; please rebuild PAR::Packer at /usr/share/perl5/vendor_perl/5.40/PAR/StrippedPARL/Static.pm line 61
Compilation failed in require at /usr/share/perl5/vendor_perl/5.40/PAR/Packer.pm line 1270.
Issue #1: it is not at all obvious to me how to rebuild PAR::Packer. I tried re-installing it with the Cygwin installer but I keep getting the same message.
So as an alternative I decided to try downgrading my Perl install from 5.40.2 to 5.40.0. I went through the appropriate steps in the Cygwin installer, and it said it was uninstalling 5.40.2 and installing 5.40.0. When finished, I check the Perl version:
bin > perl -v This is perl 5, version 40, subversion 2 (v5.40.2) built for x86_64-cygwin-threads-multi (with 3 registered patches, see perl -V for more detail)
Copyright 1987-2025, Larry Wall
Perl may be copied only under the terms of either the Artistic License or the GNU General Public License, which may be found in the Perl 5 source kit.
Complete documentation for Perl, including FAQ lists, should be found on this system using "man perl" or "perldoc perl". If you have access to the Internet, point your browser at https://www.perl.org/, the Perl Home Page.
The Cygwin installer seems quite convinced I have 5.40.0 installed. I have tried reinstalling 5.40.0 but no matter what I do nothing changes. I can't (or won't) completely uninstall Perl because that'll take all my installed packages with it, and I don't want to start over with everything.
Issue #2: How can I really truly downgrade from 5.40.2 to 5.40.0?
At the latest German Perl Workshop I held a 40 min beginner- to mid level talk about Raku (slides). It was about the habits of Perl programmers that turn contra productive with this new language. This article is a summarizing recapitulation of the pitfalls minus the intro about the history of Raku, the zef ecosystem and some general knowledge - for all those who could not attend or don't speak German.
My first code related slide showed:
use v6.c;
To revamp on the Raku versioning system but also to point out if you leave out the ".c" its actually like in Perl and would get an almost proper error message from Perl - but since the name change to Raku und having the file ending .raku .rakumod and .rakutest this once good idea lived out its usefulness.
Spacing
The first point I hammered over and over into the listeners brains was: watch out your spacing. For instance
my($ö) = 3.;
Will come back and bite you since there is no sub declared with the name my. There has to be one space after any keyword unless its unambiguous (by using a sigil e.g.). But in this case the braces could envelope a signature. To make things interesting I put feints and multiple errors into the examples. So unlike in Perl, the ö is no problem. Raku works like use utf8; is always on. But the number is illegal. You can write .5 but dangling dot is not allowed, since it could be also a dangling method call since 3 is an object from type Int. I showed this by telling about 3.WHAT and $ö.WHAT, which is "(Int)" and I had to explain the difference between value types and container types. Since $ö is not a type bound container it behaves like in Perl and may receive a string afterward. So the best way to write this example is: my $ö = 3; To level up the spice I chose the next example:
OO everywhere
my $ß' = Int->new();
And surprisingly I caught most of the audience with this blatant error. Method call is ofc the dot and not -> like in Perl but the power of customs did bite here. But the Raku compiler complains about something else first: Variable names may include an apostrophe or an hyphen, but not on the end. So this example has to be fixed into: my $ß's = Int.new(); Just to reiterate, Raku has not only types - there are types all over to the bottom and all types are Objects. Even the Classes are Objects (MOP). So $ö = 3; was just a neat way to say $ö = Int.new( 3 ); . And since types have default values the Klingon variable $ß's has the content of 0, hence its defined. After explaining that $ß's.DEFINITE is just another way to ask for defined - ness and that Int:D is not the funny sister of Int but something that enforces defined - ness we got ready for the next example.
my Int $z = Inf;
Perl would not object, but Raku does, since Inf is of type Num, not Int. Floating point numbers can be infinite but an Int just grows into what would be in Perl a bigint and in Raku is a normal Int with an irregular hunger for memory and CPU. Another pit for Raku newbs.
@a.push 7;
Doesn't feel quit right and it isn't. If you want to leave out the comma, use the braces or double colon : @a.push: 7;
$n<1;
This was reminder: watch your spaces. <> is the new qw// and also used for quoted hash slices so Raku had no way of knowing if this is an syntax error and you meant $n<1>. Which is a discussion that needed the side track to mention that there are no longer "references". A Hash container object be equally held my $h and %h.
if $a < 0 { ... }
This was a feint, no error and yes $a is no longer special. And it was a reminder round braces are optional in Raku and this is the native way to write an if statement. The I explained the new ternary op: 1 ?? 2 !! 3 which is way better visible inside larger statements and is consistent with the other ops since its more in line with other short circuit op like || and && and ? and ! are the general signs for yes and no in Raku language. It was not much of a pit since the error message was very clear and Raku just tells you: you used ? : of you meant to write ?? !! since this is the ternary op. Raku is quite good at this at some spots.
^Iterate!
for (my$i=0;$i <5;$i++) { say $i }
Yes C - style loop is still around but its spelled loop since while and until enforce boolean context, for like an comma creates a list it can iterate over and loop is neutral here enforcing no context. And besides, loop { ... } is a cleaner way to get and infinite loop and less of an (established) crutch than while (1) {}. Of course we in Perl (and Raku ?) would never use that but instead:
for (0 .. 4) { say }
Which was a great opportunity to explain yes there is still $, one of the four surviving special vars (@, $, $/ and $!) but it doesn't will be automagically inserted into @. Instead of you write for (0 .. 4) { .say } which is short for for (0 .. 4) { $.say } and there is always for (0 .. 4) { say $ }. But since I wanted teach native Raku - the way to go is: for 0 .. 4 -> $i { say $i }. The short arrow op does create a real ad hoc signature and can be used everywhere, no more special rules and with <-> $i becomes a writable variable. But there was still more honey in this example to suck, since you could compress it to: for ^5 -> $i { say $i }. So I had to explain that ^ is in Raku the ordinary way to exclude the bounds in ranges. So Raku knew this is a Range. Since ^ was to the left of the number it was the upper bound, so Raku filled in the default lower bound of zero and in list context (enforced by for) you get: 0,1,2,3,4 to iterate over. I mean how often you found annoying to write for my $i (0 .. $limit-1) { .... Its also these little things than make programming Raku refreshing just by typing for ^$limit -> $i { ..... Plus we got just another way to write if 0 <= $length < 5 { ... , it's: if $length ~~ 0 .. ^5 { ...
While on the topic of iteration I had to also point out how unclean inner workings of the the keyword each is in Perl and how much better the solution in Raku. Either you get from an hash in list context a list of pairs:
for %hash -> $pair { say $pair.key }
or you
for %hash.kv -> $key, $value { ... }
Raku has no longer autoflattening of list which is source of many surprises for seasoned Perl programmers (this is a list with 3 elements: (1,2,(3,4))). It is also to consider when iterating over cross products:
for @l1 X @l2 -> $tupel { ... }
What to say and what to put
The next pit was very unexpected one. Since everything is an object you can convert it into a String by calling on it .Str or into a string representation that could be evaluated back into same data structure with .Raku. But even more often you need .gist which gives you a nice overview and stops for instances to spill out the Array content after 100 elements. Objects like IO handles give a much nicer summary about their status is you call .gist than if you just call .Str (which is equivalent for using them in String context). And because .gist is what you want in most cases it gets silently called when using say. If you don't like that, you have to revert to print - or if you want to avoid typing "/n": use put. Yes its all laid out nicely in the documentation but still - as a newb search the bits you think you need.
What goes in and what goes out
The last chapter was about IO since its an integral part of working with Perl (and Raku). All the functionality is classes in the IO::* namespace, including the whole pathtools, cwd and more. (Raku went the batteries included route). And we have an .IO method to transmute a string into a dir or file handle. So -e "filepath" in Perl becomes "path".IO.e which I personally like more than the prominently touted "path".IO ~~ :e which does the same. slurp and spurt are of course a huge winner in beginner tutorials since its reading and writing files without any handle. Just directly from file name to string content:
my $text = slurp "filepath"; # but :
my $text = 'datei'.IO.slurp;
And you can even iterate over lines of a text file and even directories without any handle. My last example demonstrated all that.
for '/path'.IO.dir.grep: {.f} -> $file {
say '== ' ~ $file;
for $file.lines.kv -> $nr , $line {
say " $nr : $line";
}
}
P.S. Don't worry all the seek and tell stuff is till there.
Maintaining Perl 5 Core (Dave Mitchell): June 2025
Perl Foundation NewsPublished by alh on Monday 14 July 2025 12:13

Dave writes:
I spent last month working on rewriting and modernising perlxs.pod, Perl's reference manual for XS.
It's still a work-in-progress, so nothing's been pushed yet.
Summary: * 49:49 modernise perlxs.pod
Total: * 49:49 TOTAL (HH::MM)
Maintaining Perl (Tony Cook) May 2025
Perl Foundation NewsPublished by alh on Monday 14 July 2025 12:11
Tony writes:
``` [Hours] [Activity] 2025/05/01 Thursday 0.17 #23232 minor fixes to PR 1.32 #4106 cleanup, perldelta push for CI 1.48 #23225 more review 1.37 #23225 more review, thought I found an issue, testing, but
couldn’t reproduce
4.34
2025/05/05 Monday 0.72 #23242 review, testing, nothing more to say
0.95 #23244 review, testing and approve
1.67
2025/05/06 Tuesday 0.32 #22040 testing and comment 0.88 github workflow discussion, win32 performance 0.45 more github workflow, email to list 0.38 #23202 read through, comment 0.98 #4106 rebase, basic testing, open PR 23262
0.60 some basic Win32 profiling
3.61
2025/05/07 Wednesday 0.12 #4106 fix minor issue 0.22 #23259 review, testing and comment 1.22 #23263 review and approve 0.05 #23264 review and agree (thumbs up) existing comment 0.37 #23255 review, research and approve with comment 0.32 #23234 review, consider API question and approve 0.47 #23254 review, comment 0.13 #23253 review, others have pointed out problems (subscribe to PR) 0.28 #23251 review, testing and comment 0.23 #22125 rebase, basic testing, make PR 23265
2.07 #23225 more review
5.48
2025/05/08 Thursday 0.22 #23254 review updates and approve 0.10 #23259 review updates and approve 1.52 #23202 review updates, comment 0.58 #22854 research 2.10 #22854 look for stuff to document here, but it seems to
mostly be well covered in some form or another.
4.52
2025/05/12 Monday 0.42 github notifications 2.57 #22883 research, debugging, testing, long comment on #22907 0.37 #22854 minor changes, testing push and make PR 23274
0.60 #23272 try to work up a fix, comment
3.96
2025/05/13 Tuesday 0.33 #23225 follow-up 1.08 #23272 write some text and make PR 23276 0.25 #23275 review and comment 0.58 #23225 more review
1.23 #23225 more review
3.47
2025/05/14 Wednesday 0.12 #23275 comment 0.50 #23274 minor edit and follow-up 0.32 #23276 minor edit 0.08 #23279 review and approve 0.08 #23279 review and approve 1.43 #23225 more review
3.18 #23037 research, testing, comments
5.71
2025/05/15 Thursday 0.33 #23287 review and approve 0.68 #23282 update feature.pm and make PR 23288 (run into some github strangeness too) 1.40 #23225 more review 0.55 #23282 comment on #23288 0.40 #23261 comment
1.10 #23225 more review
4.46
2025/05/19 Monday 0.30 #23282 re-work docs 0.72 #23304 comment on rt.cpan ticket 0.18 #23282 more re-work docs 0.23 #23297 review and approve 0.35 #23298 review and approve 0.08 #23299 review and approve 0.25 #23301 review, checks and comment 0.08 #23302 review and approve 0.08 #23303 review and approve
1.65 #23225 more review
3.92
2025/05/20 Tuesday 0.48 #23301 review updates, testing and comment 0.23 #23307 testing 0.08 #23305 review and approve
1.52 #23225 more review
2.31
2025/05/21 Wednesday 2.92 #23225 more review, comments 1.52 #23310 debugging, fix and make PR 23312 and make issue 23313
0.53 #22883 make a PR for the perlio approach, PR 23314
4.97
2025/05/22 Thursday 1.48 #22883 fixes to PR, thinking and comment, on 23314, work on rebasing the 22987 PR 0.17 fix badly merged cygwin perldelta note PR 23316 1.63 #23225 final? pass over the complete changed files
1.65 #23225 final? pass continued and finished
4.93
Which I calculate is 53.35 hours.
Approximately 37 tickets were reviewed or worked on. ```
Perl 🐪 Weekly #729 - Videos from TPRC
dev.to #perlPublished by Gabor Szabo on Monday 14 July 2025 09:47
Originally published at Perl Weekly 729
Hi there!
The Perl and Raku Conference was held 2 weeks ago, videos are being uploaded to YouTube
Sad news: Mark Keating posted that Matt S. Trout (mst) passed away. Mark also collected the comments and publications of others.
Podcast: MetaCPAN - Underbar episode 3
Enjoy your week!
--
Your editor: Gabor Szabo.
Sponsors
Support Gabor
I started the Perl Weekly newsletter 14 years ago and (the precursor of) the Perl Maven site 20 years ago. Recently I started to write a booklet about OOP in Perl. I love providing consulting, development, and training services to companies, but I still prefer creating free content. I could do more of the latter if you also supported me. There are several ways to do that. You can do it via Patreon, GitHub, PayPal, or by buying one of my books.
Articles
A pipe operator exists on perl v5.42?
XS the easy way
Perl
This week in PSC (198) | 2025-07-04
The Weekly Challenge
The Weekly Challenge by Mohammad Sajid Anwar will help you step out of your comfort-zone. You can even win prize money of $50 by participating in the weekly challenge. We pick one champion at the end of the month from among all of the contributors during the month, thanks to the sponsor Lance Wicks.
The Weekly Challenge - 330
Welcome to a new week with a couple of fun tasks "Clear Digits" and "Title Capital". If you are new to the weekly challenge then why not join us and have fun every week. For more information, please read the FAQ.
RECAP - The Weekly Challenge - 329
Enjoy a quick recap of last week's contributions by Team PWC dealing with the "Counter Integers" and "Nice String" tasks in Perl and Raku. You will find plenty of solutions to keep you busy.
Let’s Count All of Our Nice Strings
A creative and playful dive into string processing in Perl. The code is modular, well-commented, and structured using Literate Programming style fragments.
TWC329
The solutions are crisp, Perlish, and demonstrate a good grasp of regular expressions and bitwise logic.
Counter Nice
The post tackles both parts of the challenge with thoughtful code and helpful inline commentary. It's Well-documented, beginner-friendly and a good demonstration of Raku’s expressiveness.
Perl Weekly Challenge: Week 329
Solutions leaned toward succinct, readable Perl and Raku idioms. The variety of strategies—regex, loops, data structures—showing the languages’ flexibility.
Nice Integers
The use of uniqint over a simple digit-matching regex is clean and effective—an elegant one-liner that does exactly what's needed without overcomplication.
mangling strings
Raku solutions are idiomatic and concise, leveraging regex and built-ins elegantly. An outstanding, well-organized exploration of polyglot programming applied to algorithmic problem solving.
Perl Weekly Challenge 329
The post provides elegant and efficient solutions to the tasks, demonstrating a deep understanding of Perl's capabilities. The reflective analysis adds valuable insights into the complexities of problem-solving in programming.
Counter-Nice
The post balances clarity, correctness and Perl expertise. A great read for anyone interested in clean problem-solving and Perl-specific insights.
It MUST be nice!
The post delivers solid, multi-language solutions to two algorithmic tasks—extracting distinct integers from mixed strings and identifying the longest "nice" substring—with clear thought processes and thorough commentary. The musical theater references and clever title pun, helps make technical content more approachable.
Fun with strings
The post does a great job of highlighting ambiguities in specifications. It identifies potential edge cases (a9a09a) and makes reasonable assumptions while also pointing out how easily such details can be overlooked or underspecified.
Nice Counter
It offers a clear, practical walkthrough of the weekly challenge in both Perl and Rust, showing straightforward and idiomatic solutions for each.
Endings, Elephants and Explanations
This blog post is a thoughtful and engaging walk through of Raku solutions to the challenge, woven with personal reflection and a touch of humor. It opens with a heartfelt tribute to the late MST,
Y Translate?
A clean, polished walkthrough demonstrating idiomatic solutions with attention to detail—particularly in normalization and edge-case handling. Well written and focused, with practical depth.
Not a Nice Problem to Have
An insightful, advanced and enjoyable read—ideal for those who appreciate both performance-aware coding and elegant problem-solving.
Videos
Dancer 2.0.ohh-myyy
Meet the Board
Test2::UI Howto
Git commit --pull-request
Padding Your Objects: Using Object::Pad
Perl and the Unix Philosophy
Weekly collections
NICEPERL's lists
Great CPAN modules released last week.
Events
Paris.pm monthly meeting
August 13, 2025
Paris.pm monthly meeting
September 10, 2025
You joined the Perl Weekly to get weekly e-mails about the Perl programming language and related topics.
Want to see more? See the archives of all the issues.
Not yet subscribed to the newsletter? Join us free of charge!
(C) Copyright Gabor Szabo
The articles are copyright the respective authors.
Perl `gv`module: "No matching function for overloaded 'edge'
Perl questions on StackOverflowPublished by U. Windl on Monday 14 July 2025 06:48
The manual page for the Perl gvmodule (graphviz) states:
New edges
Add new edge between existing nodes
edge_handle gv::edge (tail_node_handle, head_node_handle);
Accordingly I wrote a simple test routine:
require 5.026_001;
use warnings;
use strict;
use gv; # graphviz
# test
sub test()
{
my $result = 0;
if (defined(my $gh = gv::digraph('test'))) {
if (defined(my $nh = gv::node($gh, 'name'))) {
if (defined(my $eh = gv::edge($gh, $nh, $nh))) {
if (gv::write($gh, 'test.out')) {
print "success\n";
} else {
print STDERR "$0: failed to write output: $!\n";
}
} else {
print STDERR "$0: failed to create edge\n";
}
} else {
print STDERR "$0: failed to greate node\n";
}
} else {
print STDERR "$0: failed to greate digraph\n";
$result = 2;
}
return $result;
}
my $result = test();
When running it, it fails with
No matching function for overloaded 'edge' at ...
(Seen in SLES15 SP6)

Claim your $PERL rewards today using DappRadar with our step-by-step guide.
Guide: Get PERL During the Upcoming Bonus Rollout
Perl on MediumPublished by Perlin on Monday 14 July 2025 06:37
- Should be a Perl expert
- Should help the team to ensure a clean Perl environment in non-prod and production environment
- Strong scripting knowledge
- Strong in linux commands
- Hands on experience in implementing File Integrity Monitoring (FIM) process and sound knowledge of FIM process
- Should support with deployment
- Apache server
- Strong SQL knowledge
- Strong PostgresSQL
- Azure
- Work with ops to onboard clients and configure the new client in upstart
- Work with clients to resolve their issues
- Should have strong written and oral communications
- Should be able to independently create response to the audit questions
- Review any process or code with internal and external audit team
- Good to have enterprise Identity Lifecycle Management experience
<h3 class='likesectionHead' id='lets-count-all-of-our-nice-strings'><a id='x1-1000'></a>Let’s Count All of Our Nice Strings</h3>
RabbitFarm PerlPublished on Sunday 13 July 2025 16:54
The examples used here are from the weekly challenge problem statement and demonstrate the working solution.
Part 1: Counter Integers
You are given a string containing only lower case English letters and digits. Write a script to replace every non-digit character with a space and then return all the distinct integers left.
The code can be contained in a single file which has the following structure. The different code sections are explained in detail later.
We don’t really need to do the replacement with spaces since we could just use a regex to get the numbers or even just iterate over the string character by character. Still though, in the spirit of fun we’ll do it anyway.
Ok, sure, now we have a string with spaces and numbers. Now we have to use a regex (maybe with split, or maybe not) or loop over the string anyway to get the numbers. But we could have just done that from the beginning!Well, let’s force ourselves to do something which makes use of our converted string. We are going to write the new string with spaces and numbers to a PNG image file. Later we are going to OCR the results.
The image will be 500x500 and be black text on a white background for ease of character recognition. This fixed size is fine for the examples, more complex examples would require dynamic sizing of the image. The font choice is somewhat arbitrary, although intuitively a fixed width font like Courier should be easier to OCR.
The file paths used here are for my system, MacOS 15.4.
-
sub write_image{
my($s) = @_;
my $width = 500;
my $height = 500;
my $image_file = q#/tmp/output_image.png#;
my $image = GD::Image->new($width, $height);
my $white = $image->colorAllocate(255, 255, 255);
my $black = $image->colorAllocate(0, 0, 0);
$image->filledRectangle(0, 0, $width - 1, $height - 1, $white);
my $font_path = q#/System/Library/Fonts/Courier.ttc#;
my $font_size = 14;
$image->stringFT($black, $font_path, $font_size, 0, 10, 50, $s);
open TEMP, q/>/, qq/$image_file/;
binmode TEMP;
print TEMP $image->png;
close TEMP;
return $image_file;
}
◇
This second subroutine will handle the OCRing of the image. It’ll also be the main subroutine we call which produces the final result.
After experimenting with tesseract and other open source OCR options it seemed far easier to make use of a hosted service. OCR::OcrSpace is a module ready made for interacting with OcrSpace, an OCR solution provider that offers a free tier of service suitable for our needs. Registration is required in order to obtain an API key.
-
sub counter_integers{
my($s) = @_;
my @numbers;
my $image = write_image($s);
my $ocrspace = OCR::OcrSpace->new();
my $ocrspace_parameters = { file => qq/$image/,
apikey => q/XXXXXXX/,
filetype => q/PNG/,
scale => q/True/,
isOverlayRequired => q/True/,
OCREngine => 2};
my $result = $ocrspace->get_result($ocrspace_parameters);
$result = decode_json($result);
my $lines = $result->{ParsedResults}[0]
->{TextOverlay}
->{Lines};
for my $line (@{$lines}){
for my $word (@{$line->{Words}}){
push @numbers, $word->{WordText};
}
}
return join q/, /, @numbers;
}
◇
Just to make sure things work as expected we’ll define a few short tests.
-
MAIN:{
print counter_integers q/the1weekly2challenge2/;
print qq/\n/;
print counter_integers q/go21od1lu5c7k/;
print qq/\n/;
print counter_integers q/4p3e2r1l/;
print qq/\n/;
}
◇
-
Fragment referenced in 1.
Sample Run
$ perl perl/ch-1.pl 1, 2, 2 21, 1, 5, 7 4, 3, 2, 1
Part 2: Nice String
You are given a string made up of lower and upper case English letters only. Write a script to return the longest substring of the give string which is nice. A string is nice if, for every letter of the alphabet that the string contains, it appears both in uppercase and lowercase.
We’ll do this in two subroutines: one for confirming if a substring is nice, and another for generating substrings.
This subroutine examines each letter and sets a hash value for both upper and lower case versions of the letter as they are seen. We return true if all letters have both an upper and lower case version.
-
sub is_nice{
my ($s) = @_;
my %seen;
for my $c (split //, $s){
if($c =~ m/[a-z]/) {
$seen{$c}{lower} = 1;
}
elsif($c =~ m/[A-Z]/) {
$seen{lc($c)}{upper} = 1;
}
}
for my $c (keys %seen){
return 0 unless exists $seen{$c}{lower} &&
exists $seen{$c}{upper};
}
return 1;
}
◇
-
Fragment referenced in 6.
Here we just generate all substrings in a nested loop.
-
sub nice_substring{
my ($s) = @_;
my $n = length($s);
my $longest = q//;
for my $i (0 .. $n - 1) {
for my $j ($i + 1 .. $n) {
my $substring = substr($s, $i, $j - $i);
if (is_nice($substring) &&
length($substring) > length($longest)){
$longest = $substring;
}
}
}
return $longest;
}
◇
-
Fragment referenced in 6.
The main section is just some basic tests.
-
MAIN:{
say nice_substring q/YaaAho/;
say nice_substring q/cC/;
say nice_substring q/A/;
}
◇
-
Fragment referenced in 6.
Sample Run
$ perl perl/ch-2.pl Weekly abc
References
XS has a reputation for being hard to access and I think it's a shame because I don't think it has to be: it's mostly that the Perl API is hard. What if you offload as much logic as possible to perl, and use XS only to expose functions to perl? That would be much easier for a casual XS writer who doesn't know anything about Perl's internals.
So, in this example I will write a simple XS module for a real-life API, in this case POSIX real-time semaphores. This allows you to synchronize data between different processes or threads. At its core the API is this:
sem_t* sem_open(const char* path, int open_flags, mode_t mode, unsigned int value);
int sem_close(sem_t *sem);
int sem_unlink(const char* path);
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_post(sem_t *sem);
What's the simplest way to expose that through XS? That would look something like this:
#define PERL_NO_GET_CONTEXT
#include "EXTERN.h"
#include "perl.h"
#include "XSUB.h"
#include <semaphore.h>
MODULE = POSIX::Sem PACKAGE = POSIX::Sem
TYPEMAP: <<END
sem_t* T_PTR
mode_t T_IV
END
sem_t *sem_open(const char* path, int open_flags, mode_t mode, unsigned int value)
int sem_close(sem_t *sem)
int sem_unlink(const char* path)
int sem_wait(sem_t *sem)
int sem_trywait(sem_t *sem)
int sem_post(sem_t *sem)
Let me explain. An XS file always starts with a C section, followed by one or more XS sections declared using the MODULE keyword.
Our C section is fairly short and obvious, I'm first importing all the Perl bits that we need, this is a boilerplate that every XS module will start with. Then we include the API we want to wrap (semaphore.h).
Then we declare we want to declare the POSIX::Sem XS module. This contains a typemap and a list of functions.
The typemap declares which conversion template should be used for specific types; it will already be predefined for standard types such as int and char*, but we do need to tell it that sem_t* should be treated as a basic pointer (T_PTR), and mode_t as an integer (T_IV). Typemaps are really useful for making your XS code simpler, but sadly they're rather underdocumented.
After that, all we have to do is declare the functions in XS as they're declared in C. All the code needed to wrap the functions up and export them into Perl will be automatically generated.
Now we just need some Perl code to wrap it up:
package POSIX::Sem;
our $VERSION = '0.001';
use 5.036;
use XSLoader;
XSLoader::load(__PACKAGE__, $VERSION);
use Errno 'EAGAIN';
sub open($class, $path, $open_flags, $mode = 0600, $value = 1) {
my $sem_ptr = sem_open($path, $open_flags, $mode, $value);
die "Could not open $path: $!" if not $sem_ptr;
return bless \$sem_ptr, $class;
}
sub DESTROY($self) {
sem_close($$self);
}
sub post($self) {
die "Could not post: $!" if sem_post($$self) < 0;
}
sub wait($self) {
die "Could not wait: $!" if sem_wait($$self) < 0;
}
sub trywait($self) {
if (sem_trywait($$self) < 0) {
return undef if $! == EAGAIN;
die "Could not trywait: $!";
}
return 1;
}
sub unlink($class, $path) {
die "Could not unlink: $!" if sem_unlink($path) < 0;
}
1;
Here we use XSLoader to load the XS module and import the functions from the library. I could have chosen to leave it at that, but I chose to wrap it up in a nice object-oriented API by storing the pointer that we get from sem_open in a scalar reference so I can bless it.. Other than that all the Perl code does is turn any error into an exception. The resulting API can be used something like this:
use 5.036;
use POSIX::Sem;
use Fcntl 'O_CREAT';
my $sem = POSIX::Sem->open("foo", O_CREAT);
$sem->post;
$sem->wait;
That's all folks!
This week in PSC (198) | 2025-07-04
blogs.perl.orgPublished by Perl Steering Council on Sunday 13 July 2025 12:38
All three of us attended.
- We reviewed the perldelta entry for the CVE-2025-40909 patch, which has so far been blocking the security point releases. We reasoned out previous tentatively assumed necessary improvements to the text and ended up rejecting them and concluding that the text is perfectly adequate. The point releases can now go ahead.
- Philippe reported on the experience with the release process and thoughts on how to improve it and the release guide. Main takeways are that it would be useful to have a single source of truth for the version of Perl (e.g. for
buildtoc) and that what we think of as the release process is really a procedure for performing a state transition on the repository, where the repository constitutes the input tomakerel, and the state transition aims to trigger the correct change in the output ofmakerel. - We initiated transition to next PSC and discussed preparations for passing on an agenda for continuity.
Problems joining string content [closed]
Perl questions on StackOverflowPublished by mike joe on Sunday 13 July 2025 07:32
How can I join string content in Perl?
my $string = $q->param("us1"); # this is what entered +book +dog +cat
print join(',', $string), "\n";
This is the output I want:
"+book", "+dog", "+cat"
We all knew Matt Trout differently.
To some, he was tough. Uncompromising. Intimidating, even. He was half-man, half-thermite, a brilliant intellect with a particular way of loving something so fiercely that if you didn’t match that intensity, he might burn straight through, leaving you feeling crispy at the edges. Others have spoken about his “Get good or get out” attitude and I think it’s important to acknowledge that whilst he forged a lot of people into better programmers, it also drove others away.
But my version of Matt was the best mentor I’ve ever had. He was never condescending, in fact he seemed to have an infinite amount of belief in me and patience with me that I’m not sure what I did to deserve. When I was drowning, he’d pull me out of the water at the last minute, give me a hint, and throw me back into the deep end. I learned to swim because he never doubted that I could.
I’m someone who tends to live in her head a lot, who wonders aloud, and I’m not always the best at putting those ideas into action. Matt refused to let me coast. If I mentioned an idea he felt had merit, saying that was something that I'd hope to get round to one day, his whole face would light up. “No, Roz, you should do that now,” he’d say, and before I could weasel out of it, he’d already fetched a notebook, opened a terminal, given me a commit bit, fixed my blockers, and was patiently waiting for me to get over myself. I’d fire off objections, and he’d let me rant. Then he’d give me that look - “Are you done?” - and poke me to crack on with it.
He challenged me. But he also cheered for me, loudly, awkwardly, and sincerely. He just instinctively knew what I needed.
I also knew him personally. We had this strange, sacred little ritual. There was no name for it that stuck, that was part of the game to signal it with some melodramatic geek or metal title, like “A Long Dark Tea-Time of the Soul.” That was our shorthand for “I need to share with you the dark, shameful, horrible thoughts that are bothering me right now.” We didn’t try to fix or explain them. No armchair psychoanalysis. No running away screaming in sheer horror at the ugliness. Just two people being raw, vulnerable and human, exposing our demons to sunlight to disinfect them, robbing fear and shame of its power, knowing that we'd still be accepted by each other rather than shunned. It’s not part of any therapeutic model I’ve ever heard of, but it helped us both a lot.
But our friendship wasn’t perfect.
My husband Daimen was new to Perl, still learning, and someone Matt had taken under his wing until he very abruptly and very publicly decided wasn’t worth his time and effort. To this day we still can’t pinpoint what exactly Daimen did wrong. It wasn’t just a refusal to offer help and time going forward, but an entire character assassination. Rather than fishing him out of the pool, Matt jumped in and held my husband’s head under the water.
It was painful to witness, difficult to reconcile with my own experience, and left Daimen with a negative impression of the Perl community. For him, it wasn't TIMTOWTDI, it was There Is More Than One Way To Do It But If You Fail The mst Sniff Test You Never Realised You’d Signed Up For You’re Castigated And Cast Out.
It sadly caused a rift between us that never healed. Matt followed me from a distance, occasionally liking or responding when the topic felt “safe.” Tech. Politics. Nothing personal. Leaving the ball in my court for when I was ready to confront him about this. That’s what made it so hard to read Curtis Poe’s remembrance, about Matt feeling like he had so few friends left, because I still cared so very deeply about him. Because with the news of his death I imagined what I would say to him if given one last opportunity, and was left with the realisation that reconciliation was just a Long Dark Tea-Time Of the Soul away. One more moment of brutal honesty and grace.
But I also know that if I spent too thinking and talking about that, Matt would shoot me that look when I was done, give me a hug, and then a poke. “Right then, JFDI”.
(dlvi) 15 great CPAN modules released last week
NiceperlPublished by prz on Saturday 12 July 2025 16:41
-
App::cpm - a fast CPAN module installer
- Version: 0.997024 on 2025-07-11, with 172 votes
- Previous CPAN version: 0.997023 was 3 months before
- Author: SKAJI
-
Catmandu - a data toolkit
- Version: 1.2025 on 2025-07-07, with 191 votes
- Previous CPAN version: 1.2024 was 5 months, 21 days before
- Author: NICS
-
CGI - Handle Common Gateway Interface requests and responses
- Version: 4.70 on 2025-07-07, with 45 votes
- Previous CPAN version: 4.69 was 26 days before
- Author: LEEJO
-
Finance::Quote - Get stock and mutual fund quotes from various exchanges
- Version: 1.66 on 2025-07-05, with 142 votes
- Previous CPAN version: 1.65 was 2 months, 16 days before
- Author: BPSCHUCK
-
Future - represent an operation awaiting completion
- Version: 0.52 on 2025-07-11, with 61 votes
- Previous CPAN version: 0.51 was 8 months, 20 days before
- Author: PEVANS
-
Inline - Write Perl Subroutines in Other Programming Languages
- Version: 0.87 on 2025-07-10, with 39 votes
- Previous CPAN version: 0.86 was 5 years, 6 months, 1 day before
- Author: INGY
-
IO::Socket::SSL - Nearly transparent SSL encapsulation for IO::Socket::INET.
- Version: 2.095 on 2025-07-10, with 49 votes
- Previous CPAN version: 2.094 was 21 days before
- Author: SULLR
-
Object::Pad - a simple syntax for lexical field-based objects
- Version: 0.821 on 2025-07-12, with 46 votes
- Previous CPAN version: 0.820 was 4 months, 13 days before
- Author: PEVANS
-
PAR::Packer - PAR Packager
- Version: 1.064 on 2025-07-08, with 55 votes
- Previous CPAN version: 1.063_001 was 1 year, 14 days before
- Author: RSCHUPP
-
Perl::Tidy - indent and reformat perl scripts
- Version: 20250711 on 2025-07-11, with 143 votes
- Previous CPAN version: 20250616 was 25 days before
- Author: SHANCOCK
-
Plack::Middleware::Session - Middleware for session management
- Version: 0.35 on 2025-07-07, with 40 votes
- Previous CPAN version: 0.34 was 9 months, 14 days before
- Author: MIYAGAWA
-
POE::Component::IRC - A fully event-driven IRC client module
- Version: 6.95 on 2025-07-07, with 12 votes
- Previous CPAN version: 6.94 was 5 days before
- Author: BINGOS
-
Term::ReadLine::Gnu - Perl extension for the GNU Readline/History Library
- Version: 1.47 on 2025-07-06, with 23 votes
- Previous CPAN version: 1.46 was 2 years, 4 days before
- Author: HAYASHI
-
Test::Differences - Test strings and data structures and show differences if not ok
- Version: 0.72 on 2025-07-07, with 21 votes
- Previous CPAN version: 0.71 was 1 year, 8 months, 25 days before
- Author: DCANTRELL
-
WebService::Fastly - an interface to most facets of the [Fastly API](https://www.fastly.com/documentation/reference/api/).
- Version: 11.01 on 2025-07-08, with 18 votes
- Previous CPAN version: 11.00 was 25 days before
- Author: FASTLY
The Weekly Challenge - Guest Contributions
The Weekly ChallengePublished on Friday 11 July 2025 00:00
A pipe operator exists on perl v5.42?
blogs.perl.orgPublished by karjala on Wednesday 09 July 2025 00:06
You know how many languages have a "pipe" operator, either ready or in the making? Like PHP, here, for example: https://laravel-news.com/the-pipe-operator-is-coming-to-php-85
Well, Perl v5.42 (almost) has that too! Check these examples:
$ perl -E 'say "Alexander"->&CORE::substr(1, 3);'
lex
$ perl -E 'say ","->&CORE::join(qw/ 10 20 30 /);'
10,20,30
I believe this would work with any user defined or imported subroutine too, instead of the core functions (there you get to omit the "CORE::").
This Language Was Declared Dead in 2008 — I Just Got a $150K Offer for It
Perl on MediumPublished by Kavya's Programming Path on Tuesday 08 July 2025 11:07

The world laughed, the memes flew, the hype moved on. But guess who’s still getting paid?
(dlv) 13 great CPAN modules released last week
NiceperlPublished by prz on Monday 07 July 2025 09:51
-
App::rdapper - a simple console-based RDAP client.
- Version: 1.15 on 2025-07-03, with 20 votes
- Previous CPAN version: 1.14 was 3 days before
- Author: GBROWN
-
CPANSA::DB - the CPAN Security Advisory data as a Perl data structure, mostly for CPAN::Audit
- Version: 20250703.001 on 2025-07-03, with 23 votes
- Previous CPAN version: 20250617.001 was 15 days before
- Author: BRIANDFOY
-
JSON::Schema::Modern - Validate data against a schema using a JSON Schema
- Version: 0.614 on 2025-06-28, with 12 votes
- Previous CPAN version: 0.613 was before
- Author: ETHER
-
Module::CoreList - what modules shipped with versions of perl
- Version: 5.20250702 on 2025-07-03, with 44 votes
- Previous CPAN version: 5.20250528 was 1 month, 5 days before
- Author: BINGOS
-
Mojolicious - Real-time web framework
- Version: 9.41 on 2025-07-03, with 507 votes
- Previous CPAN version: 9.40 was 1 month, 21 days before
- Author: SRI
-
Moose - A postmodern object system for Perl 5
- Version: 2.4000 on 2025-07-04, with 333 votes
- Previous CPAN version: 2.2207 was 1 year, 5 months, 14 days before
- Author: ETHER
-
Net::DNS - Perl Interface to the Domain Name System
- Version: 1.51 on 2025-07-04, with 28 votes
- Previous CPAN version: 1.50_01 was 3 days before
- Author: NLNETLABS
- perl - The Perl 5 language interpreter
- Version: 5.042000 on 2025-07-03, with 2128 votes
- Previous CPAN version: 5.040002 was 11 weeks and 4 days before
- Author: BOOK
-
Rex - the friendly automation framework
- Version: 1.16.1 on 2025-07-05, with 86 votes
- Previous CPAN version: 1.16.0.3 was 5 days before
- Author: FERKI
-
Sisimai - Mail Analyzing Interface for bounce mails.
- Version: v5.4.0 on 2025-07-01, with 78 votes
- Previous CPAN version: v5.3.0 was 3 months, 3 days before
- Author: AKXLIX
-
SPVM - The SPVM Language
- Version: 0.990077 on 2025-07-04, with 36 votes
- Previous CPAN version: 0.990076 was before
- Author: KIMOTO
-
Syntax::Construct - Explicitly state which non-feature constructs are used in the code.
- Version: 1.043 on 2025-07-04, with 14 votes
- Previous CPAN version: 1.042 was 20 days before
- Author: CHOROBA
-
Test::MockModule - Override subroutines in a module for unit testing
- Version: v0.180.0 on 2025-07-03, with 17 votes
- Previous CPAN version: v0.179.0 was 10 months, 4 days before
- Author: GFRANKS
Perl 🐪 Weekly #728 - Perl Conference
dev.to #perlPublished by Gabor Szabo on Monday 07 July 2025 05:28
Originally published at Perl Weekly 728
Hi there,
Last week was packed with two major gatherings for Perl enthusiasts: The Perl Community Conference (Hybrid) Summer 2025 and The Perl and Raku Conference 2025. Both events brought together developers, contributors and fans from around the world, whether in person or online.
Unfortunately, I couldn't attend either conference this time but I'm eager to catch up on what I missed. If you were there, I'd love to hear about your experience. Makoto Nozaki has already shared one: event report, thank you for that. If others have insights, talks or highlights to share, please do.
For those curious about the talks, the official PCC 2025 schedule is available here. I spotted a live talk link on Facebook and joined briefly, but due to audio issues, I had to drop out. Fingers crossed that recordings or slides will be shared soon for those of us who couldn't attend fully.
One thing, I noticed this year, there wasn't much pre-event promotion for individual talks or maybe I just missed it on social media? Either way, if you couldn't make it, keep an eye out for uploaded slides and summaries. There's always something new to learn!
That's all for now, enjoy the rest of the newsletter and happy coding..
--
Your editor: Mohammad Sajid Anwar.
Sponsors
Support Mohammad
This edition of the Perl Weekly newsletter was prepared by Mohammad Sajid Anwar. He has been editing every 2nd issue for 7 yeas already! Also, he has been running The Weekly Challenge for several years now. He does both of these in his free time because he loves doing them. However, it is really nice to know that there are 34 people who feel that his efforts are worth the recognition by supporting him with 5-10 USD / month via Patreon. If you are one of those people I'd like to thank you and if you are not yet, I'd like to encourage you to sign up to Patreon and start supporting him!
Announcements
Perl 5.42.0 Released: Performance Gains, Feature Refinements, and Key Security Fixes
The Perl development team has officially released Perl v5.42.0, introducing a blend of modern language features, thoughtful refinements to long-standing behavior, and a round of performance and security enhancements.
This week in PSC (197) | 2025-06-26
Another quick update from Perl Steering Council.
Articles
Neural Networks and Perl
Stands out by exploring neural networks in Perl, a less common but intriguing combination. It provides a hands-on implementation.
Keep on Mocking with a Key, Girrrrl
A fun, practical guide to mocking in Perl that balances humor with solid technical content. Ideal for Perl developers looking to improve their testing skills with minimal jargon.
TPRC Greenville 2025
A short and effective event report for TPRC 2025. If you missed the event then you must read this.
Vibe Coding a Perl interface to a C library
An excellent technical walkthrough for intermediate-to-advanced Perl programmers needing to interface with C libraries. It presents practical code with useful explanations of the binding process.
Vibe coding a Perl interface to a foreign library - Part 2
An excellent resource for Perl developers needing to create robust, production-ready C library bindings. It has deep technical knowledge with practical implementation advice.
Attending the Perl Community Conference (Hybrid) July 3-4
The Weekly Challenge
The Weekly Challenge by Mohammad Sajid Anwar will help you step out of your comfort-zone. You can even win prize money of $50 by participating in the weekly challenge. We pick one champion at the end of the month from among all of the contributors during the month, thanks to the sponsor Lance Wicks.
The Weekly Challenge - 329
Welcome to a new week with a couple of fun tasks "Counter Integers" and "Nice String". If you are new to the weekly challenge then why not join us and have fun every week. For more information, please read the FAQ.
RECAP - The Weekly Challenge - 328
Enjoy a quick recap of last week's contributions by Team PWC dealing with the "Replace all ?" and "Good String" tasks in Perl and Raku. You will find plenty of solutions to keep you busy.
A Good String Is Irreplaceable
A strong, educational post with working code and creative problem-solving. The core is robust and instructive.
TWC328
Provides compact Perl implementations for each task. Avoids over-engineering (e.g., uses simple loops and hashes for uniqueness).
All Good
The post is well-structured with a conversational tone, making it accessible to readers of varying skill levels.
Kinda Pre-Disastered
A solid, enjoyable post that balances technical rigor with Dave’s signature conversational style. Ideal for Perl enthusiasts and coding challenge participants.
Replace and Remove
A practical, no-frills post perfect for coders seeking quick solutions. It delivers correct and efficient code.
regexs everywhere!
A technically excellent post that stands out for its rigorous mathematical approach and unique dual-language perspective.
Perl Weekly Challenge 328
A thorough, well-written post that combines mathematical insight with practical coding solutions. Excellent for learners who want to understand both the "how" and "why" behind the challenges.
Regexes Replacing All Good Strings?
A solid, well-explained solution with efficient implementations. Great for learners looking for clear, optimized Perl solutions to algorithmic problems.
Good Old-Fashioned Replacement Boy?
A masterclass in making technical content both educational and entertaining. Perfect for Perl enthusiasts who appreciate personality in programming tutorials.
Questions are good
A no-nonsense, technically solid post that delivers working solutions with Perl best practices. Ideal for experienced developers who prefer code-first explanations.
Good Replacement
While away, Rust is still the favourite choice for blog post. Code maintains clarity without sacrificing efficiency.
A good question
A fun, well-written post that balances technical content with readability. Great for beginners and those who appreciate a casual yet informative take on coding challenges.
The Weekly Challenge : Week 328
A no-nonsense, efficient walkthrough of the weekly challenge. Ideal for those who prefer concise, performance-conscious solutions.
In case of doubt, use a regex
A refreshing, regex-focused take on the problem that highlights Perl’s flexibility. Great for regex enthusiasts and those exploring unconventional solutions.
Property is Theft, Theft is Good
A clever, well-explained solution with a touch of humor. Perfect for those interested in optimization tricks and Perl’s practical elegance.
Rakudo
2025.26 Release #184
Weekly collections
NICEPERL's lists
Great CPAN modules released last week.
The corner of Gabor
A couple of entries sneaked in by Gabor.
Object Oriented Programming - OOP in Perl
You can read the book free of charge on this web site, or if you feel like supporting the writing of this book you can buy it and get a pdf and epub version of it.
Events
Purdue Perl Mongers - TBA
July 9, 2025
Paris.pm monthly meeting
July 9, 2025
Paris.pm monthly meeting
August 13, 2025
Paris.pm monthly meeting
September 10, 2025
You joined the Perl Weekly to get weekly e-mails about the Perl programming language and related topics.
Want to see more? See the archives of all the issues.
Not yet subscribed to the newsletter? Join us free of charge!
(C) Copyright Gabor Szabo
The articles are copyright the respective authors.
<h3 class='likesectionHead' id='a-good-string-is-irreplaceable'><a id='x1-1000'></a>A Good String Is Irreplaceable</h3>
RabbitFarm PerlPublished on Sunday 06 July 2025 17:39
The examples used here are from the weekly challenge problem statement and demonstrate the working solution.
Part 1: Replace all ?
You are given a string containing only lower case English letters and ?. Write a script to replace all ? in the given string so that the string doesn’t contain consecutive repeating characters.
The core of the solution is contained in a single subroutine. The resulting code can be contained in a single file.
The approach we take is to randomly select a new letter and test to make sure that it does not match the preceding or succeeding letter.
-
sub replace_all{
my($s) = @_;
my @s = split //, $s;
my @r = ();
{
my $c = shift @s;
my $before = pop @r;
my $after = shift @s;
my $replace;
if($c eq q/?/){
push @r, $before, $replace if $before;
push @r, $replace if!$before;
}
else{
push @r, $before, $c if $before;
push @r, $c if!$before;
}
unshift @s, $after if $after;
redo if $after;
}
return join q//, @r;
}
◇
Finding the replacement is done in a loop that repeatedly tries to find a relacement that does not match the preceding or following character. Since the number of potential conflicts is so small this will not (most likely require many iterations.
Just to make sure things work as expected we’ll define a few short tests.
-
MAIN:{
say replace_all q/a?z/;
say replace_all q/pe?k/;
say replace_all q/gra?te/;
}
◇
-
Fragment referenced in 1.
Sample Run
$ perl perl/ch-1.pl atz peck graqte
Part 2: Good String
You are given a string made up of lower and upper case English letters only. Write a script to return the good string of the given string. A string is called good string if it doesn’t have two adjacent same characters, one in upper case and other is lower case.
We’ll define a subroutine for detecting and returning non-good pairs of letters. We know we’re done when this subroutine returns undef.
We’ll call these pairs of letters bad pairs. To see if we have a matching pair we’ll just compare the ascii values.
-
sub bad_pair{
my($s) = @_;
my @s = split q//, $s;
return undef if!@s;
{
my($x, $y) = (ord shift @s, ord shift @s);
if($x == $y + 32 || $x == $y - 32){
return chr($x) . chr($y);
}
unshift @s, chr($y);
redo unless @s == 1;
}
return undef;
}
◇
-
Fragment referenced in 5.
We use that bad_pair subroutine repeatedly in a loop until all bad pairs are removed.
-
sub make_good{
my($s) = @_;
{
my $bad_pair = bad_pair $s;
$s =~ s/$bad_pair// if $bad_pair;
redo if bad_pair $s;
}
return $s;
}
◇
-
Fragment referenced in 5.
The main section is just some basic tests.
-
MAIN:{
say make_good q/WeEeekly/;
say make_good q/abBAdD/;
say make_good q/abc/;
}
◇
-
Fragment referenced in 5.
Sample Run
$ perl perl/ch-2.pl Weekly abc
References
Weekly Challenge: A good question
dev.to #perlPublished by Simon Green on Sunday 06 July 2025 12:25
Weekly Challenge 328
Each week Mohammad S. Anwar sends out The Weekly Challenge, a chance for all of us to come up with solutions to two weekly tasks. My solutions are written in Python first, and then converted to Perl. It's a great way for us all to practice some coding.
Task 1: Replace all question marks
Task
You are given a string containing only lower case English letters and ?.
Write a script to replace all ? in the given string so that the string doesn't contain consecutive repeating characters.
My solution
For this one, I will start with the Perl solution. Strings in Perl are mutable (i.e. they can change). For this task, I loop through the position of each character with the variable idx, and assign the char variable to the character at that position.
sub main ($input_string) {
my $solution = $input_string;
foreach my $idx ( 0 .. length($solution) - 1 ) {
my $char = substr( $solution, $idx, 1 );
if ( $char ne '?' ) {
next;
}
If char is not ?, I move onto the next character. I then have an hash called %letters. If idx is not 0 (i.e. the first character), I add the preceding character to the letters hash. If idx isn't the last character's position, I add the following character to the letters hash. The letters hash now has the preceding and following character.
my %letters = ();
if ( $idx > 0 ) {
$letters{ substr( $solution, $idx - 1, 1 ) } = 1;
}
if ( $idx < length($solution) - 1 ) {
$letters{ substr( $solution, $idx + 1, 1 ) } = 1;
}
The last step to is replace the question mark with a letter, using the following rules.
- If
lettersdoes not have ana, replace it witha. - If
lettersdoes not have anb, replace it withb. - Replace it with
c.
if ( not exists $letters{'a'} ) {
substr( $solution, $idx, 1 ) = 'a';
}
elsif ( not exists $letters{'b'} ) {
substr( $solution, $idx, 1 ) = 'b';
}
else {
substr( $solution, $idx, 1 ) = 'c';
}
}
say '"', $solution, '"';
}
The Python solution uses the same logic, but builds the solution value letter by letter. In Python, strings are immutable (i.e. they cannot be changed).
def replace_all_questions(input_string: str) -> str:
solution = ''
for idx, char in enumerate(input_string):
if char != '?':
solution += char
continue
letters = []
if idx > 0:
letters.append(input_string[idx - 1])
if idx < len(input_string) - 1:
letters.append(input_string[idx + 1])
if 'a' not in letters:
solution += 'a'
elif 'b' not in letters:
solution += 'b'
else:
solution += 'c'
return solution
Examples
$ ./ch-1.py a?z
"abz"
$ ./ch-1.py pe?k
"peak"
$ ./ch-1.py gra?te
"grabte"
$ ./ch-1.py gra?be
"gracbe"
Task 2: Good String
Task
You are given a string made up of lower and upper case English letters only.
Write a script to return the good string of the given string. A string is called good string if it doesn’t have two adjacent same characters, one in upper case and other is lower case.
My solution
This is more straight forward, although GitHub Copilot got rather confused with what was expected. For this task, I start by setting the solution variable to the same as the input string.
I then have an loop that runs continuously. Within that is an inner loop with the variable idx which starts at zero until two less than the length of solution. This is done as we don't want to check the last character, it has no next character.
If the letter at that place is upper case and the next letter is the same but lower case, or visa versa, I remove those two characters, and the outer loop will be called again.
If no characters are removed, the else: break clause will exit the outer loop.
def good_string(input_string: str) -> str:
solution = input_string
while True:
for idx in range(0, len(solution)-1):
char = solution[idx]
if ((char.isupper() and solution[idx + 1] == char.lower()) or
(char.islower() and solution[idx + 1] == char.upper())):
solution = solution[:idx] + solution[idx + 2:]
break
else:
break
return solution
The Perl solution follows the same logic, but with a slightly different syntax.
Examples
$ ./ch-2.py WeEeekly
"Weekly"
$ ./ch-2.py abBAdD
""
$ ./ch-2.py abc
"abc"
I bought some new keyboards
rjbs forgot what he was sayingPublished by Ricardo Signes on Saturday 05 July 2025 12:00
I go to Melbourne a couple times a year, for work. It’s where our HQ is, and it’s good to have time in person with my colleagues. It used to be that most of this time was spent at big tables or in front of whiteboards. There’s still quite a lot of that, but the past two or three times I was in Australia, I spent a much larger chunk of time at a desk, programming. Surely not the majority of my time, but enough time that I cared about the ergonomics. So, last time I was there, I dug through the spare hardware cupboard and put together the best workstation I could. It was… not great. Fortunately for me (in one sense, anyway), one of my colleagues was on leave. I boldly appropriated his desk, which was much better hardware than my scavenging had gotten me. The thing that I ended up grumbling about, though, was the mouse and keyboard.
Let’s be clear: This was all on me! I don’t need the Australian office to stock all my favorite hardware for the 7% of the year I spend there. On the other hand, I did feel like I wanted to plan ahead for next time. I keep a bag of stuff in the Melbourne office to make the trip easier. This is mostly cables, adapters, and toiletries. It’s much nicer to have my favorite Merkur safety razor waiting for me than to spend two weeks using disposables. My plan was to put a keyboard and mouse in that bag. Maybe a little USB hub. Simple, right? Well…
I’m fussy about my keyboards. I’m not a keyboard wonk, I think. I know just a little bit about mechanical keyboards, and I know what I like. Mostly, what I like is full size (with numeric keypad) keyboards, in the traditional layout, with clicky switches. When I started thinking about taking a keyboard to Australia, I owned three mechanical keyboards. All Ducky brand, all with Cherry MX blue switches. Surely, I could just go order one of these, right? Well, it didn’t seem like it. They were backordered everywhere I looked. The most likely-seeming one was the Ducky One 3, which looked about right. I almost just ordered it, but then I remembered: a lot of keyboards are now configurable via software. That sounded interesting, so I did some more digging.
The short version is that there’s an open-source firmware for keyboards called QMK, and lots of keyboards use it. It lets you remap keys, program macros, and do that sort of thing. A coworker asked, “Why is that better than just updating your settings in macOS?” The answer is, basically: If you tell your keyboard that its caps lock key should act like a control key, it will do that on every computer you attach it to, with no configuration required. The longer form answer is that you can do all sorts of weird stuff that macOS would never allow.
Ducky doesn’t support QMK (or other reprogramming) on most of their keyboards. The one I did find with QMK is the “Ducky One X ‘Inductive Keyboard’”. They bill it as “the world’s first inductive keyboard”. I don’t really understand what an inductive switch is. I looked into it a little. I do know that it’s not a clicky blue switch, though, and I know that it costs a lot more than my usual keyboards. Pass.
Now I was sort of in open territory where I didn’t want to be: picking a new kind of keyboard. This was agony. I was trying to remember what other models I’d used. I looked into one in the US office (where most of the keyboards are mechanical, with brown switches), and was reminded how much I dislike clamped-in stabilizer bars. (More on that later, maybe.) Figuring out just what I wanted seemed like it was going to be a pain. Also, the news kept telling me about massive impending tariffs, which were surely going to punish me for delaying on ordering hardware from abroad.
Keyboard 1
Eventually, I found myself looking at Keychron. I knew of them only because a few years ago I bought a four-pack of Keychron C1 mechanical keyboards for the office for $50. In my mind, they were some sort of Johnny-come-lately cheap-o brand. On the other hand, their site had an enormous variety of keyboards, and I couldn’t find anything online that backed my view. I decided to order a K10 Max QMK, which ticked a couple key boxes: it’s programmable with QMK and it’s wired (but also works over Bluetooth or with its own transceiver)
The problem was that it didn’t have a blue switch option. Red, Brown, or (I’m not kidding) Super Banana. Reds and browns, I knew, were no good for me. Super banana, I was not sure, but I didn’t want to commit to something I might not like. The good news is that the K10 is hot-swappable. That means that after you pull the keycap off of the switch, you can pull the switch out, too, and replace it. I gather that some gamers put different switches in for different keys. I don’t really know why, but it’s something like “I want a really low activation force for my movement keys but a really quick reset for my trigger keys”. I didn’t care enough to look into it. My goal was to put in one hundred blue switches and dump all the originals into a box.
I ordered the K10 along with a tube of 110 Cherry MX blue switches. When it arrived, I played around for a bit, but quickly got to work pulling off all the keycaps and pulling out all the switches. This was easy, although the switch-pulling tool that came with the keyboard was a bit rough on my fingers. With all the (red) switches pulled, it was time to put in the blues. Inserting is not as simple as pulling, sadly. At the bottom of each switch are two stiff wires that slide into receivers in the keyboard. The upper part of the switch has two little arms that snap into place when the switch is seated. If the wires aren’t perfectly lined up, or aren’t straight, they will buckle or bend, and then the switch won’t form a circuit with the PCB.
This means that for each switch you insert, you first need to look carefuly at the leads to make sure that they’re straight and whole. It’s a little slow-down, but not so bad.

I put on some music and got to work. Pretty soon, I’d replaced all the switches and put the keycaps back on. I opened the Keychron Launcher to begin phase two. The Keychron Launcher is a web interface for managing the keyboard’s settings. It amazes me, because it uses a web API called WebHID, which gives your browser access to your HID devices per se. I had to use Chrome, but when I did, let let me flash my keyboard’s firmware and update its keymap. It also had a key tester that let me test every single key. When one or two didn’t work, I pulled the switches and replaced them with spares. Pretty soon, the whole keyboard worked and had a mapping I liked. I was delighted. Sure, it was expensive, but it has a great weight, it has the switches I like, and I could keep tweaking the keyboard layout until I was perfectly happy.
Keyboard 2
It was good enough that I went right ahead and ordered another one, that one for my office. In the week since my first order, the price had gone up $20 — almost certainly tariff-related. This was just the first problem.
I ordered that second keyboard on April 6th, and I had it in my hands on the 10th. I stuck around a little late after work to swap out the switches. Pretty soon I had a keyboard that worked great… except for eleven keys, as seen here.

Many of the keys worked if I replaced my aftermarket blue switches with the original reds that were included, so my first theory was that I had quite a lot of busted blue switches. I know the failure rate on switches is high, so I went with that theory and ordered more. Unfortunately, when they arrived, it didn’t help. The reds still worked and the blues didn’t. Except, sometimes the reds didn’t. Mostly it was centered around one part of the board, and if I pressed hard, they would start or stop working. I called on my friend Jesse, established member of the keyboard-industrial complex. He worked with me for a while, prompting me to do stuff I never would’ve done, like close circuits with a wire lead. Eventually, he was having me send close-up photos of the printed circuit board that all the keys slot into. He said, “Oh, look at those sockets! They’re at a bit too much of an angle, you’re not going to get good connections with those at all, they need re-soldering correctly.”
Here’s a photo from around that time. Is it a bad socket? I’m not sure, I had a hard time seeing it, but Jesse seemed convinced, and I believe him. But this might be an unrelated photo. My point is, this is what I was stuck thinking about!

Friends, I did not spent $190 on a pre-assembled keyboard just to be stripping
things down to the PCB and re-soldering them! I’m not that kind of computer
nerd! Frustrated, I wrote in to Keychron, who said they’d send me another PCB.
Not as good as another keyboard, but I could do this. Eventually, the package
came. I carefully disassembled my keyboard: I removed the keycaps, then the
switches, then the top case, then the plate, then then PCB. I attached the new
PCB, put on the top case, and put in the switches. I was not bold enough to
put on all the keycaps, though. I fired up the Keychron Launcher and entered
key test mode. Almost perfect. Everything worked except for one key that
I’d hardly need: t.
Probably I could key in a whole paragraph, using only such glyphs as remained available. I mean, I had a double dozen symbols under my fingers, plus one! Only one member of our language’s ABCs was missing. Sadly, my keyboard was here for work, and my job is hardly one focused on producing source code lipogram. If I was gonna use my new device, I would need all 101 keys working.
I took the keyboard apart again to see how things looked. They didn’t look good.

Look at this a little while and you’ll see one of those black shapes isn’t in line with the others. It’s not just bent, it’s totally disconnected. It had fallen off the PCB and was sitting under it inside the keyboard. That’s the socket, and it’s how the keyswitch connects to the circuit so that, when pressed, the switch closes the circuit. If the socket falls off, the key absolutely will not work.
“What do I do now?” I asked Jesse.
“You solder it,” he said. “Good luck.”
Fortunately, I had a soldering iron, never used. I got in the 2023 Bag of Crap from Jesse’s company. He reported its original price as $2.60. After trying to use it, I’m sorry to say that it was closer to $0 in value. Mine did not heat up at all when plugged in. It probably could’ve been used as an awl, but what I needed was a very hot metal point, and I didn’t want to heat it up on coals. I moaned and wailed in the office, and my coworker Kurt said he’d bring in a proper soldering iron for me to use. I was still pretty frustrated at being in this position, but if it was going to get my keyboard working, fine.
He brought in a soldering iron and magnifiers, and I got to work. Five or six times, on three or four distinct days, I tried to solder that socket back on. I couldn’t get it done. On one hand, it’d been decades since I last soldered anything. On the other hand, I felt sort of incompetent.
I emailed Keychron again: Look, I said, the new PCB is at least as bad off as the old one. I tried hard to not ask you for more, because I’m sure the tariffs are a problem, but at this point I think I’ve done enough. Can you just ship me a new complete keyboard so I am not forced to perform work on yet another replacement part?
“No problem,” they said. “We’ll send you a new printed circuit board.”
Steam came from my ears, and Kurt pitied me. “Let’s fix that,” he said.

Kurt sat down and methodically performed about a dozen steps, including the three that I’d performed, plus another nine that probably made any part of the job actually work. With the piece soldered on, I reassembled they keyboard and 99% of the switches worked. I took a deep breath, pressed down on the remainder, and then they all worked. I screwed everything together and put on the keycaps. Everything was going great…
…until the very, very last keycap. Remember at the very beginning, I said I like to get a keyboard with a ten-key numeric keypad? I really do, and I use it! The last key I was putting on was the keypad’s “Enter” key, at the far bottom right. They keycap went on, but it didn’t bounce up when pressed. It stayed down. They Keychron keyboard had the screwed-in stabilizers like I like, but the stabilizers on this key were now partly stuck in place. They’d move if pushed or pulled, but it took more force than the spring in the keyswitch. Here’s a demonstration:
I asked Jesse, but he didn’t have any advice that avoided disassembling the dang thing again. I really, really wanted to avoid that. I’d had this thing for two months, and I just wanted to have it in place and working. I searched the internet, I wiggled at the crossbar of the stabilizer, but nothing helped.
Here’s the thing about stabilizers: the wider or longer the key, the more important the stabilizer is, and the closer to the edge you his the key, the more important the stabilizer is. The keypad’s enter key is pretty short, at 2u, and I’d mostly hit it toward the middle, anyway. I didn’t need a stabilizer! Taking the stabilizer out would be a keyboard-disassembling task. On the other hand, I could mangle the keycap so that it wouldn’t snap onto the stabilizer, and would only connect to the switch. I got a spare keypad enter key, I got a pair of pliers, and I fixed that keyboard.

Now I have working, clicky, programmable, lovely keyboards on my desks at work and at home. I’m pleased with them. On the other hand, this was a stupid amount of work, given the cost of the things. I think I’d be happy to buy another Keychron, and certainly I’d like my next keyboard (if I ever have to buy another) to be programmable with something like QMX. On the other hand, I only wanted hot-swappable keys for the sake of getting blues. I think my next keyboard will have to come preassembled with blue switches, preferably soldered right on by somebody else.
After this was all over, I took Kurt out for some beers as thanks, which came with the bonus of getting me the pleasure of his company for a couple hours. Next time, I’ll also do that without all the soldering.
Vibe coding a Perl interface to a foreign library - Part 2
Killing-It-with-PERLPublished on Friday 04 July 2025 00:00
Of makefiles and alienfiles
In the second part of this series, we turn to the chatbot’s output for bringing in the foreign (C) Bit library dependency in Perl using Alien.
The C library uses Make as a build system (here is the makefile that was provided as context to Claude if you are interested), to create static and dynamic versions of the Bit library using one of three compilers (gcc, Intel’s icx and clang), targetting NVIDIA and AMD GPUs1. The makefile makes the two versions of the library, the CPU benchmarks, the GPU benchmarks and the tests, but does not include a make install step in order to stress the chatbot’s quality of representation of the Alien process and its ability to generate good code for less travelled build paths.
The task presented to the chatbot, is to look into the makefile and make an Alien module to bring the dependency in Perl. A basic Alien module will use a recipe, i.e. an alienfile, a Perl installer2 and a skeleton package, e.g. something along the lines
use strict;
use warnings;
package Alien::Bit;
$Alien::Bit::VERSION = '0.01';
use parent qw( Alien::Base );
=head1 NAME
Alien::Bit - Find or install the Bit library
=head1 VERSION
version 0.01
=head1 SYNOPSIS
Installs the Bit library, used to manipulate bitsets and their packed containers
=head1 DESCRIPTION
...
=cut
1;
to build the distribution. For most Aliens, the action (usually, but not always) takes place inside the recipe of the alienfile:
- Establish if the dependency already exists in the system (this is known as a
systeminstall), and if does not exist do ashareinstall - For
shareinstalls, download/fetch the code (or the executable) of the dependency - Use the build system of the dependency3 to make the libraries and/or the executables that the dependency provides
- Test that those were built properly
- Gather the libraries and/or executables and place them in a folder accessible by the user of the
Alienmodule - Set up an environment or
Perlpackage variables that the package should export to the user - Do any clean-up that is necessary
Various plugins are available to automate this process, especially if one uses a standard build path, e.g. make, make test, make install. With tens of Alien modules in metacpan, and the extensive documentation of the Alien ecosystem one would expect the chatbot to deliver something functional out of the box, but does it?
Claude slops the Alien
A sane output (but most definitely NOT the only one possible output) when the chatbot is prompted to generate an Alien distribution is the skeleton code for the package and the alienfile.
Let’s see what Claude actually gave us in
Part 1 (the code is reproduced below for easy reference):
# /media/chrisarg/Software-Dev/Bit/perl-wrapper/lib/Alien/Bit.pm
package Alien::Bit;
use strict;
use warnings;
use parent 'Alien::Base';
use File::Spec;
sub dynamic_libs {
my $class = shift;
# Try to find the library in common locations
my @potential_paths = (
# From the build directory
'/media/chrisarg/Software-Dev/Bit/bit/build/libbit.so',
# System paths
'/usr/local/lib/libbit.so',
'/usr/lib/libbit.so',
# Environment variable if set
$ENV{BIT_LIB_PATH} ? File::Spec->catfile($ENV{BIT_LIB_PATH}, 'libbit.so') : ()
);
foreach my $path (@potential_paths) {
return $path if -f $path && -r $path;
}
die "Could not find libbit.so library. Please set BIT_LIB_PATH environment variable to its location.\n";
}
sub include_dirs {
return (
'/media/chrisarg/Software-Dev/Bit/bit/include',
'/usr/local/include',
'/usr/include',
$ENV{BIT_INCLUDE_PATH} || ()
);
}
1;
The first thing we notice in the solution, is that no alienfile is provided; everything is coded in the module (.pm) file. This is fine as far as Perl is concerned (after all TIMTOWTDI and all that), but it is a bit unusual in an Alien world. Contrasting the generated code to the alienfilerecipe we also notice the following:
- There is no check for the dependency; this may be the correct way to do it (after all the
Bitmakefile neither installs the library in a system directory where it can be found, nor it provides a*.pcfile that a manager such aspkg-configcan query. Or it can be an error of omission, but we will never know. - There is no attempt to use
Bit’s makefile to build the library, i.e. Claude implicitly assumes that the build has taken place and that the library already exists in the system. This is too big an assumption for a dependency that is supposed to be used by others (not just the owner of the dependency!). - In fact Claude apparently makes the stronger assumption that I will be the only user, since it hardcodes the directory path in the
Alienpackage code.
The end result well qualifies for AI slop: the package code is never going to be useful to anyone else than me, and it will fail if I move things around (or if a non-standard install directory is used e.g. what if I use /opt, rather than /usr/ to install stuff ?
The initial experience is an example of the Greek slang phrase : “one cannot paint eggs with farts”, a phrase we asked Grok to commend on recently.
Can Claude help out an Alien?
Is it possible to help Claude out a little bit more? I followed up with the prompt
Look at the Alien::Bit module you generated. Does it appear to you that the code will work in someone's else
computer/workstation with all the hardcoded paths? Don't you think that a better solution would be to provide
an alienfile ? Can you reflect on the code and how it can be enhanced to deliver a robust Alien module that
does not hardcode paths? Can you reflect on what you could have done better?
For reference here is the code you provided to me below: ...
I also provided access to my initial alienfile
My own alienfile is NOT without issues but it adheres to the logic of a typical recipe:
- It defaults to a shared install (as I provide no system install in the dependency makefile)
- It downloads the dependency source from github4
- It builds the libraries and executables (for the tests/benchmarks)
- It runs them and croaks if the tests did not pass
- It installs the libraries for use by Perl inside the distribution
- It sets the relevant runtime properties (e.g. include flags/library names, though not in an OS aware way)
Claude’s response to this prompt is listed below: ___________________________________________
Critical Reflection on the Alien::Bit Implementation
You’re absolutely right, and I apologize for the poor implementation I provided earlier. The code I generated contains serious flaws that would make it fail on most systems:
Problems with the Previous Implementation
-
Hardcoded Paths: The module contains paths specific to your system (
/media/chrisarg/Software-Dev/Bit/...) which would fail on any other computer. -
Missing Alien::Build Integration: The code tries to manually implement what Alien::Build already does well, but does it incorrectly.
-
Ignores Platform Differences: It doesn’t properly handle different operating systems and their file naming conventions.
-
Poor Error Handling: It would fail in unpredictable ways when the library isn’t found.
Better Approach: Using alienfile Properly
The alienfile you’ve shared is a much better approach. It:
- Downloads the code from a consistent source
- Builds it correctly
- Installs files to the appropriate locations
- Sets up the necessary runtime properties
A proper Alien::Bit module should simply inherit from Alien::Base and let Alien::Build handle the heavy lifting:
package Alien::Bit;
use strict;
use warnings;
use parent 'Alien::Base';
1;
That’s it! The complexity belongs in the alienfile, which your version handles well.
Improvements to Your alienfile
While your alienfile is already quite good, here are some enhancements:
-
Platform Awareness: Already good with
$^O eq 'MSWin32'checks - Better Library Detection:
plugin 'PkgConfig' => ( pkg_name => 'bit', ); - Improved Error Messages:
if (not -e $runTests_exec) { print "Can't find test executable at $runTests_exec\n"; return; # Skip tests rather than failing } - System Installation Detection:
probe sub { # Check standard lib directories for libbit my @paths = ('/usr/lib', '/usr/local/lib'); foreach my $path (@paths) { return 'system' if -f "$path/libbit.so"; } return 'share'; };
Lessons Learned
-
Never Hardcode Paths: Always use relative paths or platform-specific functions to find files.
-
Use the Alien::Build Ecosystem: It handles most complexity for you.
-
Test on Different Platforms: An implementation that works on one system may fail on others.
-
Follow Established Patterns: The Alien module ecosystem has well-established patterns to follow.
I should have provided a proper alienfile-based implementation from the start rather than a flawed manual approach. Thank you for the opportunity to reflect on this and improve my understanding of Alien modules. ___________________________________________
Having caught out “slopping” it was able to focus to a more reasonabe implementation, which however still implicitly assumes that make install takes place and despite the lip service to platform awareness is still probing for the library in a very Linuxy way.
Let’s see if we can get it to fix things by another round of prompting:
Let me push back on what you provided: 1) the makefile has no `make install` target and does not
generate a .pc file, so do you think that the 'PkgConfig` is appropriate? 2) forget completely my
alienfile and generate one yourself (taking into account the answer to the first question)
3) reflect on your code
You’re absolutely right to push back on my suggestions. Let me address your points:
1) Regarding PkgConfig
You’re correct - suggesting plugin 'PkgConfig' was inappropriate since your Makefile doesn’t have an install target and doesn’t generate a .pc file. This would never work. This was a serious oversight on my part.
2) New alienfile from Scratch
Here’s a properly designed alienfile that addresses the actual requirements:
use alienfile;
use strict;
use warnings;
# Define metadata and build requirements
configure {
requires 'Path::Tiny';
requires 'File::Copy::Recursive';
requires 'HTTP::Tiny';
requires 'Carp';
};
# Always use the share approach (build from source)
# since there's no reliable system package detection
probe sub { 'share' };
share {
# Import necessary modules
use Path::Tiny qw( path );
use File::Copy::Recursive qw( dircopy fcopy );
use Carp qw( croak );
# Set source repository information
my $repo_url =
'https://github.com/chrisarg/Bit/archive/refs/heads/master.zip';
# Configure download
start_url $repo_url;
plugin 'Download';
plugin 'Extract' => 'zip';
# Build configuration
plugin 'Build::Make';
# Define build commands
build [
# Standard build process
['%{make}'],
# This builds the test program too
['%{make} test'],
# This builds the benchmark programs
['%{make} bench']
];
# Post-build file handling - copy files to staging directory
after 'build' => sub {
my ($build) = @_;
# Determine destination directory
my $stage_dir = path( $build->install_prop->{stage} );
my $source_dir = path( $build->install_prop->{extract} );
# Create lib and include directories
my $lib_dir = $stage_dir->child('lib');
my $include_dir = $stage_dir->child('include');
$lib_dir->mkpath;
$include_dir->mkpath;
# Copy shared library to lib directory
my $build_dir = $source_dir->child('build');
my @libs;
# Handle different platform library extensions
if ( $^O eq 'MSWin32' ) {
@libs = $build_dir->children(qr/\.(dll|lib)$/);
}
elsif ( $^O eq 'darwin' ) {
@libs = $build_dir->children(qr/\.(dylib|a)$/);
}
else {
@libs = $build_dir->children(qr/\.(so|a)$/);
}
# Copy each library file
foreach my $lib (@libs) {
my $dest = $lib_dir->child( $lib->basename );
$lib->copy($dest) or croak "Failed to copy $lib to $dest: $!";
print "Copied library: ", $lib->basename, "\n";
}
# Copy test and benchmark executables
my @executables;
if ( $^O eq 'MSWin32' ) {
@executables = $build_dir->children(qr/\.(exe)$/);
}
else {
@executables = grep {
-x $_
&& !-d $_
&& $_->basename !~ /\.(so|dylib|dll|o|a)$/
} $build_dir->children;
}
foreach my $exe (@executables) {
my $dest = $lib_dir->child( $exe->basename );
$exe->copy($dest) or croak "Failed to copy $exe to $dest: $!";
chmod 0755, $dest; # Ensure executable permissions
print "Copied executable: ", $exe->basename, "\n";
}
# Copy header files
my $headers_dir = $source_dir->child('include');
my @headers = $headers_dir->children(qr/\.h$/);
foreach my $header (@headers) {
my $dest = $include_dir->child( $header->basename );
$header->copy($dest) or croak "Failed to copy $header to $dest: $!";
print "Copied header: ", $header->basename, "\n";
}
};
# Set runtime properties for client code
gather sub {
my ($build) = @_;
my $prefix = $build->runtime_prop->{prefix};
# Set include and library paths
my $include_dir = path( $prefix, 'include' )->stringify;
my $lib_dir = path( $prefix, 'lib' )->stringify;
# Set compiler flags
$build->runtime_prop->{cflags} = "-I$include_dir";
# Set linker flags with appropriate library name
$build->runtime_prop->{libs} = "-L$lib_dir -lbit";
# Store raw paths for Platypus FFI
$build->runtime_prop->{ffi_name} = "bit";
$build->runtime_prop->{include_dir} = $include_dir;
$build->runtime_prop->{lib_dir} = $lib_dir;
# Print confirmation
print "Alien::Bit configured with:\n";
print " cflags: ", $build->runtime_prop->{cflags}, "\n";
print " libs: ", $build->runtime_prop->{libs}, "\n";
print " ffi_name: ", $build->runtime_prop->{ffi_name}, "\n";
print " include_dir: ", $build->runtime_prop->{include_dir}, "\n";
print " lib_dir: ", $build->runtime_prop->{lib_dir}, "\n";
};
# Run tests after installation
test sub {
my ($build) = @_;
my $lib_dir = path( $build->install_prop->{stage}, 'lib' );
# Define test executable names based on platform
my $test_exe = $^O eq 'MSWin32' ? 'test_bit.exe' : 'test_bit';
my $bench_exe = $^O eq 'MSWin32' ? 'benchmark.exe' : 'benchmark';
my $openmp_exe = $^O eq 'MSWin32' ? 'openmp_bit.exe' : 'openmp_bit';
# Get full paths
my $test_path = $lib_dir->child($test_exe);
my $bench_path = $lib_dir->child($bench_exe);
my $openmp_path = $lib_dir->child($openmp_exe);
# Run main tests if available
if ( -x $test_path ) {
print "\n**************** Running Bit Tests ****************\n";
my $test_output = `$test_path 2>&1`;
print $test_output;
if ( $test_output =~ /All tests passed/m ) {
print
"\n**************** Bit tests passed successfully ****************\n";
}
else {
croak("Bit tests failed");
}
}
else {
print "Test executable not found at $test_path - skipping tests\n";
}
unlink $test_path; # Clean up test executable
# Run benchmarks if available
if ( -x $bench_path ) {
print
"\n**************** Running Bit Benchmarks ****************\n";
my $bench_output = `$bench_path 2>&1`;
print $bench_output;
unlink $bench_path; # Clean up benchmark executable
}
else {
print
"Benchmark executable not found at $bench_path - skipping benchmarks\n";
}
# Run OpenMP benchmarks if available
if ( -x $openmp_path ) {
print
"\n**************** Running Bit OpenMP Benchmarks ****************\n";
my $openmp_output = `$openmp_path 1024 1000 1000 4 2>&1`;
print $openmp_output;
unlink $openmp_path; # Clean up OpenMP benchmark executable
}
else {
print
"OpenMP benchmark executable not found at $openmp_path - skipping OpenMP benchmarks\n";
}
# delete object files that end in .o
my @object_files = $lib_dir->children(qr/\.o$/);
foreach my $obj_file (@object_files) {
$obj_file->remove;
print "Removed object file: ", $obj_file->basename, "\n";
}
};
};
3) Reflection on This Code
My previous responses contained several serious flaws:
-
Misunderstanding Your Project Structure: I didn’t properly understand that your Makefile doesn’t have an install target or generate pkg-config files.
-
Improper Alien Patterns: I suggested using
PkgConfigwithout verifying if it would actually work. -
Excessive Focus on XS/FFI: I focused too much on implementation details rather than getting the core Alien module correct first.
The new alienfile I’ve provided addresses these issues by:
- Using Path::Tiny for more robust file operations
- Properly handling platform differences for library extensions
- Not assuming the existence of pkg-config files
- Adding better error handling and reporting
- Including comprehensive file copying to ensure all necessary components are available
- Setting proper runtime properties for downstream modules
- Adding platform-specific executable detection
This alienfile should provide a solid foundation for your Alien::Bit module. Once this is working correctly, you can focus on the FFI or XS wrappers that use it.
___________________________________________
Looking at the code and the explanation, it seens that Claude is “getting” it a little bit better and there is some limited “insight” into the reasons the first and secnd prompt generated (“excessive focus on XS/FFI”); if it were a human, we’d say that the Chatbot commited the bias premature closure by making all these assumptions and rushing to a solution. But of course the chatbot is not human, and even in its enlightened state after 3 rounds of interactions, it continues to hallucinate: there is not a single element of XS in my (or its!) code and no assumption in the alienfile that either XS or FFI will be used. A small technical detail is that alienfile generated fails to clean up the test/bench executables and the object files generated by the makefile.
Conclusions
Despite all the hype out there about AI assisted coding, there are several potential pitfalls for the end user:
- The chatbot tools require substantial subject matter expertise (and guidance) to deliver a good result
- The widespread assumption that a non technically experienced end user can achieve God status with these tools is unfounded (contrast the difference between Claude’s initial and final solution)
- Even after multiple prompting and interactions to refine the solution, key elements (e.g. the cleanup) will be missing in action
- Constant vigilance for hallucinations, omissions and biases is required5
At the end though, I was happy (for now!) with the Claude modifications of my alienfile, and I ended up replacing my own in the Alien::Bit package (after adding the cleanup code!)
-
At the time of this writing, the makefile has been tested only for NVIDIA GPU compiled with gcc ↩
-
This is usually a
Makefile.PLorBuild.PLor in my case a dist.ini since I am makingPerlmodules using Dist::Zila ↩ -
In our case this is the
makefile, butAlienscan useCmake,Mesonand other build systems ↩ -
I don’t use
Aliens’ github plugins for this, because I may be switching to gitlab in the near future ↩ -
The regex that copies static and dynamic libraries was also missed by the chatbot, and I had to manually insert prior to release. This omission by Claude was missed in a previous release of this github page ↩
rjbs in Rio, part ⅲ
rjbs forgot what he was sayingPublished by Ricardo Signes on Wednesday 02 July 2025 12:00
I’d had four days in Rio so far (and one in Miami, better left unmentioned). I had covered lots of ground for things I wanted to see, and also lots of things I didn’t know I should see. I had eaten so, so much cassava. I had lots of things left unseen, lots of food left uneaten, and just about two days left to fill. I think I made good use of my time, but I definitely left things to do… next time?
Monday
Monday, I was on my own again for most of the day. This is not a complaint. Breno and Barbara were incredibly generous with their time! Also, even though I usually enjoy touring around with people, it can be good to wander alone, with no worry about whether you’re bring a frightful bore to your companion. I had a handful of things on my potential agenda for the day, but I only ended up visiting two of them: Parque Lage and the Botanical Garden.
Many, many times, I had to remind myself that Parque Lage is not Portguese for “Lake Park”. It’s named after Henrique Lage. I don’t know much about him, but he seems to have been a very wealth industrialist in the early 20th century, so I’m okay not knowing more, I think. Now, the land around his mansion is a large public park with lots of tree cover and plenty of interesting features. When I was there, I don’t think the building was open for visiting — or at least I couldn’t find an open entrance. Instead, I walked around the grounds, looked at ponds, hiked through overgrown paths, and took a lot of photos.


I was there for a good two hours, just walking and looking around. It’s a little odd that I don’t have more to say, but I think it’s all in the photos. Once in a while I sat down and read a chapter or two of a book. I took a photo for an older couple walking together. At one point, I accidentally walked the wrong way, left the path, wandered through the woods for a while, and found a surprise view of the city through the trees:

What else is there to say? If I lived nearby, I’d go there often to sit and read and make take a little lunch with me.
Afterward, I had meant to walk a little south to the lagoon and walk south along it to the city’s botanical garden. I forgot, though, and just walked straight down R. Jardim Botânico, which was sort of a boring walk. It wasn’t bad, and I did some people watching, but mostly it was uninteresting. Eventually, though, I came to the garden, which was not uninteresting. I spent four hours walking through the gardens, only partly because I had such a hard time navigating them.
If I ran the botanical garden, I’d be pushing Apple and Google to add a bunch more detail to their maps, because the paper map they handed out did not cut it. I had a hard time finding almost everything, but in the end it all worked out. I’ll try to summarize some of the best things I saw:
There was a “biblical garden”, full of plants mentioned in the Bible. The plaque for each one provided a chapter and verse for where to find them.
There was a primitive hut among a bunch of trees, and all I could think of was the botanical gardens in The Shadow of the Torturer, where the narrator encountered a similar (also seemingly South American) hut.
There was an orchid house with many kinds of orchid in bloom.
There was a garden of only medicinal plants, including notes on what cultures used them, and for what purposes.
There was a big section of cacti, with a surprising amount of diversity.
There were the obligatory Japanese garden and rose garden.
Also, there were monkeys.



Probably there are people who know how to write compelling, detailed, informative notes on a visit to a place like this. I’m not one of them, though. I’ll say this: I enjoyed the place enough that I spent four hours there and might have stayed longer if I didn’t have anywhere to be. Oh, and if the food was better. I had a pretty mediocre salad there, which was absolutely my own fault. I should’ve eaten something on the walk.
After the garden, I headed back to my apartment, cooled off a little, and did a quick bout of shopping. My plan was to meet Breno nearby for dinner and drinks. We went to Boteco Belmonte and hung out for a good while, trying small plates and having a few drinks. The food was good, and the company was better. Despite my small lunch and all my walking, I wasn’t terribly hungry, or I would’ve kept exploring the menu. I had my last caipirinha of the trip, but I also decided to try their Moscow Mule. It was a strange one, with the ginger added as a sort of creamy foam on top. I’m not sure I’d order it often, but it was fun as a weird surprise.

I had meant to see some other things on Monday, but I was pretty happy with the hours spent just looking at the outdoors. In retrospect, I just wish I’d gotten one more caipirinha, to go. Or maybe on the way back to my apartment.
Tuesday
Tuesday was my last day! My flight out of Rio was at 23:00, and I had to leave my apartment around eleven. Barbara and Breno graciously invited me to come by, leave my bags, and spend the day. I spent the morning packing, running a few more errands, and finishing off most of my groceries.
On my way to their place, my phone ran out of data. I’d bought an eSIM with Airalo, which was mostly just fine. (Actually, the service I got in Brazil was not as good as what I’d gotten elsewhere, but it was totally adequate.) I’d even topped it off the previous day, but I think that all my roaming in the parks had me using more data than I thought. As my Uber got me closer to their place, I realized that the map wasn’t updating, and Discord was offline. I knew their address, and I thought I remembered how to contact them, but once I was out of the car, I was stumped. Eventually, I received an SMS from Breno, and I went back to his place and got in. I had misremembered how to ring him from the front gate!
Inside, I bought more data. More importantly, I got a tour of their place, had some chit chat, and then it was time for lunch. Lunch was homemade vegan moqeueca, with plantains replacing the fish. It was delicious. I’m pretty sure that my grandmother sometimes made a similar fish stew, but I haven’t yet confirmed this with my siblings. Anyway, it was great, and was followed by a dessert of passionfruit and condensed milk. Yum!

After lunch, Breno and I dropped his daughter at school and stopped into Casa Roberto Marinho, a large house that’s been converted into a gallery space. It was good, and was the nth place I’ve seen in the past few years featuring art depicting Laocoön. Weird? I don’t know.
From there, the plan was to see the one absolute must-see thing in Rio: the giant Christ the Redeemer statue. The statue is 98’ tall, atop a 26’ pedestal, atop a 2,300’ mountain. You can see it from all sorts of places in the city. I saw it from Sugarloaf. I saw it from the beach. I saw it from the highway while the police searched my bags. It was everywhere! Also, it was going to have an incredible view of the city.
The problem is… the weather was absolutely miserable. Every day until Tuesday had been sunny and clear, but Tuesday it was cloudy, windy, and raining. We hoped it would clear up before we went up, but it didn’t. I wasn’t too fussed, really. From up close, I knew I’d see the whole statue. Still, it was not the ideal weather for it. Breno was a sport and drove us up the mountain, where we caught a train to the top.
Here’s a view of the weather taken near where we caught the train:

An aside: I had called this train a “funicular” when talking to friends, but further research tells me that it isn’t one. It is a “rack railway”, where the train is driven by a cog along a toothed rail. This allows for much steeper gradients than a normal rail line. It was pretty cool, and from inside the train, you could definitely see and feel the slope at which the train was traveling. This particular railway is the Corcovado Rack Railway, and I will definitely be reading more about it later.
Once we got to the top, the situation was both better and worse than I’d imagined. In some directions, we could see quite a ways, and I could recognize places I’d been or had heard of. In others, there was just a dense fog. It was pretty obvious that on a good day, you’d be able to see forever, and that the view of the city would be absolutely gorgeous. I wasn’t even disappointed, though. The view was still great, and the statue was really impressive. I was also delighted to find out the pedestal on which the Christ stands house a tiny, tiny church. We stepped inside briefly to get out of the wind, but we didn’t stay long, and I didn’t get a photo. It seemed a little uncouth to do so.
The weather up there wasn’t great. It was probably 55 or 60ºF, rainy, and windy. Breno was clearly miserable, and also seemed sort of baffled that I wasn’t. What can I say? Back here in Philly, we get way down below freezing, so 55ºF and windy is merely annoying. If the view had been better, I might’ve stuck around while he got out of the rain and off to pick up his kid. As it was, I saw everything there was to see pretty quickly, and we both got out of there and onto the train.


Back at their place, we had good while to sit around, talk, and have dinner. “We’ll order pizza,” they said, “but it’s going to be terrible compared to anything in the states.” I didn’t lie and say it wouldn’t be. I’ve had pizza outside the states, I know how it goes. (It was actually tasty, it just wasn’t good pizza.) After that, it was time to finally leave Rio. I got an Uber, got to the airport, and eventually flew home with no difficulty. I had plenty of things left in Rio that I could’ve stayed to do, but as always, it was really good to get home to my people.
I had meant to bring something for Barbara and Breno. I didn’t know they’d be such exemplary hosts, but either way it would’ve been gracious. I at least remembered to bring something for their daughter: Gritty. What better thing to bring as an ambassador from Philadelphia? Fortunately, he was well received, and I felt some civic pride at Gritty’s continued ability to make life a little better.

Anyway, if I go again, I’ll remember to bring a bottle of Malört or something!
As for whether I’ll go again… it’s hard to know. I’m surprised I went at all, honestly. There isn’t much natural pressure to visit South America. Work doesn’t send me there, conferences haven’t tried to entice me. It’s expensive to get to, even if it’s cheap to spend time there. Now that I’ve been, I could imagine spending more time there and enjoying it. On the other hand, there is a lot of the planet left that I haven’t even seen once. I think I’ll have to play it by ear.
In the meantime, I’ll be looking for the best caipirinha in Philadelphia. Wish me luck.
rjbs in Rio, part ⅱ
rjbs forgot what he was sayingPublished by Ricardo Signes on Tuesday 01 July 2025 12:00
After a rocky start, I had two great days in Rio, leaving me about four days of vacation. This meant lots more walking around, a little more beach, a bunch more food (70% cassava, 20% pork, 10% other), more forró music, and not enough caipirinhas. If you didn’t read “rjbs in Rio, part ⅰ”, you should start there.
Saturday
Friday, I ended my day by watching the sunset, having a beer, and listening to two different bands on the way back to my apartment. How would I top that?
Fortunately, I had help. Breno and Barbara were back on the scene to show me around to cool things I would never have done on my own. I had a lazy morning of scrambed eggs and orange juice, and some amount of walking around the neighborhood. By this point, I’d decided that all the fearmongering around getting mugged in Rio was wildly overblown, but it did seem like I should pay attention to where I wandered, so I didn’t head too far in unknown directions. I did see a bunch more shops, including things that I probably should’ve tried eating, but didn’t. A little after ten, though, I headed to the farmer’s market at General Glicério street. I was interested in lots of the things, but stuck to the suggestions: a pastel (sort of like an empanada), a tapioca (like a taco or crêpe made with cassava), and caldo de cana (sugarcane juice). I posted a lot of photos in Flickr, but I’ll highlight this one, the tapioca:

It doesn’t look like much, but it was delicious. Breno and his daughter had one with nutella and banana — a classic pairing to stuff into anything. I had the more traditional cheese and coconut, which seemed weird but tasted great. I was also simultaneously pleased and weirded out by the shell. It was soft and chewy, and had a subtle flavor that I can’t describe. I would eat many more, with many different fillings.
We ran into a bunch of their friends and their friends’ kids, which made for a good farmer’s market experience. Who doesn’t like watching little kids play in a crowded but basically safe space? Eventually, though, we headed out toward Tacaca do Norte. I don’t know anything about this place other than it was billed as the place to get açai. Also, Brazil had already been billed as the place to get açai, so this was meant to be the best of the best. I had actually never had the stuff, although it’s definitely been sort of everywhere here. It just seemed like it would be some boring fruity health food.
There was some debate over whether I should get a huge order or a tiny order. We settled on tiny (I was so full already!), but what we got seemed pretty big to me! If you haven’t had an açai bowl (or maybe if you’ve only had whatever it is we serve in the US), I guess I’d say it’s a bit like frozen yogurt or mashed frozen bananas, like a cold, sweet, stiff pudding. It came with two little pots, one of tapioca beads and one of granola. I love putting granola into goo, so that was great. Even so, I couldn’t eat more than half of it. Even if I’d been very hungry, I’m not sure I could’ve. Meanwhile, people all around me were eating it by the liter.

After that, we split up. Breno and I continued on alone to CRAB, a museum of local and indigenous crafts. This was very cool, and had both traditional-style objects and contemporary reinterpretations. I’m pretty sure that a few of the things I saw were also in my grandmother’s house. Did she ever visit Brazil? I have no idea.
Rather than any photos of CRAB, though, here’s one of Central do Biscoito (Biscuit Central), a cookie store with a weirdly compelling mascot:

After that, I think there was some sort of general walking around, but it led us toward the Candelária Church, a beautiful (but slightly dilapidated) church. Across the street, there were June Festival celebrations, and that’s where we were headed. One of Breno’s friends was going to be part of the celebration, as a stilt walker. This event was good value. We watched a bunch of stilt walking, heard a bunch of music, saw some unexpected Capoeira, and even ran into Breno’s brother and family! We saw the thing that had been the Olympic torch when Rio hosted. Also, critically, we got caipirinhas.


We lingered a good long while, but eventually we were pretty beat (or maybe I was beat and Breno was polite) and we headed out. I think this was my first time riding the Rio Metrô, the subway. I picked up a subway pass as a souvenir. These are great souvenirs: they’re cheap, they don’t take up space, and they’re unambiguously associated with the place you went. This one was even better. It’s called a RioCard, which is an anagram of Ricardo.
The subway was clean, easy to ride, and felt safe. I rode it again alone a couple times, and have no complaints. Breno and I chatted the whole time, even as he overshot his stop by accident and accompanied me to mine on purpose. When I got back to my apartment, I took off my shoes, called home, and zoned out until it was time to sleep.
Also, here’s a picture of Breno’s niece wearing my hat.

Sunday
I have no recollection or photos of Sunday morning. I think that’s when I explored a street market near my apartment. It was pretty cool, and I bought a nice aloha shirt. The seller told me I should go a size smaller, and I didn’t listen, but I think she was right. Gloria suggests it should be easy to have shortened, so I might just do that! I also hit the grocery store (my local Zona Sul) and picked up some soap and shampoo, so I could get cleaner. I felt a little weird about buying so much for my three remaining days, but I felt better about not being gross.
I met Breno and his daughter near Biscuit Central, and we headed to the Metropolitan Cathedral of Saint Sebastian. Coming to Rio, I knew that this was one of my top priorities to see. The photos made it clear that I’d be happy with it. In person, it was even better. It was beautiful. It made great use of the light while still providing a somber space. It felt like it really fit into the place it was, and it was still clearly a cathedral. I have seen many cathedrals, and even the best are often just very well constructed versions of “yet another cathedral”. This wasn’t that. Also, as we approached I could still smell the frankinsence from the morning’s mass.



I want to learn more about the place, including what required aspects of cathedral design it fulfilled in unusual ways. That seems certain to be a thing. Seeing my photos, Mark Dominus said, “A solid refutation of the people who complain about Brutalism.”
The plan had been to take the old fashioned tram from the cathedral to the way-uphill Bohemian neighborhood of Santa Teresa, but the line for the tram was two and a half hours long, which didn’t seem worth it. We got an Uber. Up in Santa Teresa, we looked around shops and watched trams go by, which was a pretty decent substitute for actually riding the thing. Eventually, Barbara met us and we got lunch: feijoada.
Feijoada is (I am told) the national dish of Brazil. It originates in Portugal, but let’s get real: it’s meat, beans, and rice, so it’s something people eat everywhere. It was served with collard greens and tapioca flour, and it was great. Could I have eaten our three person order? Yes, probably, but it’s surely also good that I didn’t try to. (Also, it would’ve been rude.) There is no photographic evidence, but I think I had a caipirinha there. We went to Bar Simplesmente, which apparently is a great place to go for feijoada. It certainly seemed like it to me!

The other notable part of the meal was the fried hunks of cassava. At first I said, “Hey these potatoes are great!” Almost as soon as I said it, I realized it wasn’t potato, and Barbara said, “This is cassava.” I said, “This is just like the yuca fries they used to serve at the Cuban place we liked.” Barbara politely explained that cassava and yuca are the same thing, and my mind was totally blown. I feel like I really should’ve know this, but I didn’t. Then again, I don’t live in a place where every single meal contains cassava!
From there, we walked a bit more and got some coffee. I usually only drink mocha lattes, but these weren’t commonly on offer in Rio, so mostly I just had tea. Here, though, I got a cappucino, which was good! (I’ve had them before and not liked them.) We saw a small exhibit of a fashion designer’s work in a cool gallery space with a great view. Soon, though, we came to the Escadaria Selarón.
The Escadaria Selarón is a (pretty long!) outdoor staircase. If asked, I’d say they led from Santa Teresa “all the way down” to Lapa, but I’m not really sure. At the bottom, we could see the huge, defunct aqueduct that the tram rides across. The point isn’t the destination, though, it’s the stairs themselves. They’re covered in tiles, and the work was done over twenty years by Jorge Selarón, an artist who lived in the area.
The steps were pretty popular, with lots of other tourists there to see, but they weren’t crowded or annoying, and we took our time wandering down and looking at the tiles.


After the steps, Breno and I carried on alone, heading to Glória market and the nearby June Festival celebration. Breno was very keen on me trying a bunch of sweets, so he bought a bag and we sat around drinking beer and eating candy. This was better than it sounds. I think the best thing we had was pé de moleque. As far as I’m concerned this is just shiny peanut brittle (the best kind of peanut brittle), but is weirdly pitched as being a local thing for Brazil. The one we got here was actually soft, sort of like a Pay Day bar, but much nicer. My only photo of the sweets is pretty bad, so I won’t put it in here. Instead, here’s me with Glória station, which made me think of Gloria every time I saw it, of course.

We’d meant to take a bike ride after this, but instead we sat around talking until it was dark and we were beat. This was good! Breno and I (and Barbara, on other occasions) spent a lot of time talking about this and that. Often this was work, sometimes politics, and sometimes movie, TV, and books. Most notably, though, I got a lot of Brazilian history, which was all interesting and valuable as I explored the place. More than once, I saw a monument or building that I understood much better because of a bit of history I’d learned earlier in the week.
From Glória station, Breno went home and I went back to my apartment in Ipanema, where I called home and caught up, then stared at the wall for a while until it was time to sleep.
Every night, I was watching a little Resident Alien. It was good travel TV. Not too stressful, sort of funny, and easy to stop watching when vacation was over. If I couldn’t sleep, I’d watch one more episode. Sunday night, as I wrapped up one last episode, I got a message from my sister that my dad had gone to the hospital. (He’s fine now.) I waited up to get more information, and while doing that decided to floss my teeth again. Doing that, I managed to pop the crown off one of my molars, which led to another hour or so awake, searching the web for “dental adhesive brands Brazil”. Eventually, I just cleaned everything involved and jammed it back in my mouth. It stayed put until I got home, but it meant I avoided peanut brittle until I got back!
Monday, I was on my own, so it was no problem to sleep in, and so staying up too late thinking about my teeth was no problem. More on the last two days in another post.
Vibe coding a Perl interface to a C library - Part 1
dev.to #perlPublished by chrisarg on Tuesday 01 July 2025 03:10
Introduction
In this multipart series we will explore the benefits (and pitfalls) of vibe coding a Perl interface to an external (or foreign) library through a large language model.
Those of you who follow me on X/Twitter (as @ChristosArgyrop and @ArgyropChristos),
Bluesky , mast.hpc, mstdn.science,
mstdn.social know that I have been very critical of the hype behind AI and the hallucinations of both models and the
human AI influencers (informally known as botlickers in some corners of the web).
However, there are application areas of vibe coding with AI, e.g. semi-automating the task of creating API from one one language to another, in which the chatbots may actually deliver well and act as productivity boosters.
In this application area, we will be leveraging the AI tools as more or less enhanced auto-complete tools that can help a developer navigate less familiar, more technical and
possibly more boring aspects of the target language's 'guts'. If AI were to deliver in this area, then meaningless language wars can be averted, and wrong (at least in my opinion) reasons
to prefer one language, i.e. the availability of some exotic library, may be avoided.
For my foray in this area, I chose to interface to the library Bit that I wrote to support text fingerprinting for some research
applications. The library based on David Hanson's Bit_T library discussed in
Chapter 13 of "C Interfaces and Implementations"
has been extended to incorporate additional operations on bitsets (such as counts on unions/differences/intersections of sets) and fast population counts in both CPU and GPU
(with TPU implementations coming down the road). Hence, this is a test case that can illustrate the utility of Perl in using code that executes transparently in various hardware assets.
Similar to Hanson's original implementation (after all, my work is based on his!) the library interface is implemented to
an Abstract Data Type in C; a crucial aspect of the implementation is to manage memory and avoid leaks without looking (at all, or as little as possible!) under the hood.
For our experiments we will use Claude 3.7 Thinking Sonnet through the Github Copilot vscode interface. This is going to be a multipart series post that will be published throughout the summer.
Our focus will be on interactions between me and the bot, and in particular critiquing the responses it has given me for both high level (e.g. choice of approach) and technical aspects of the project.
The Prompt
For the prompt I provided the "bit.c", "bit.h", makefile and the readme file of the Bit github repository as context to Claude and then I issued the following:
Look at the bit.h file that defines two abstract data types Bit_T and Bit_T_DB
and their interfaces in C. I would like to wrap these interfaces in Perl.
The build process will consist of using the Alien package in Perl to make bit available to Perl.
Explore possible options for the creation of the interface:
A. Creation of the bit C library :
1) compiling bit.c and bit.h as dynamic libraries
2) compiling bit.c nd bit.h into a static library
B. Interfacing with the bit C library from Perl:
1) using SWIG i files
2) using Platypus::FFI
3) using Inline::C
4) using XS
Since you are an expert with deep knowledge of the Perl ecosystem, consider pros and cons of
each approach. and then recommend the optimal Consider lightweight options for encapsulating
the Bit_T and Bit_T_DB abstract data types as Perl objects.
Provide wrapping recommendations targetting a beginner, intermediate and experienced Perl
programmer since those may differ. When providing recommendations , consider the dependencies
that are required for each implementation and highlight them in your analysis.
Once you have provided the recommendation, provide the implementation of the wrapper for
these 3 programmer levels. To reduce the token output (and your risk of hallucinating),
provide a full implementation of the wrapper for the beginner level and only the
changes (if any) that are required for the intermediate and advanced programmer levels.
In my prompt specification, I clearly specified that
- linkage to the foreign library could be either as a static or a dynamic object,
- the desired way to package the dependency for use in Perl is an Alien package
- all four possible ways to interface to a foreign library from Perl should be considered.
- asked it to consider the problem of wrapping from the perspective of Perl developers with different levels of expertise.
Note that I gave the bot considerable freedom over the "low" level aspects of wrapping (type of library, choice of the cross-language interface),
but restricted it in terms of how I wanted the library served.
Furthermore, I guided it to consider alternative viewpoints and level of expertise, providing a unique opportunity to test Claude's
representation1 of conversations about wrappers. Finally, I alerted the chatbot to consider the token-sequence length dependent risk of hallucinations and
tried to limit the length of the output of the alternative implementations.
Claude's Response
The output based on this prompt is shown below (inside the horizontal lines); the formatting was also part of the output
Perl Wrapper for Bit_T and Bit_T_DB C Library
Let me analyze the options for creating a Perl interface to the Bit_T and Bit_T_DB C library and provide implementation recommendations for programmers at different experience levels.
A. Creation of the Bit C Library
1. Dynamic Library Approach
I see the Makefile already creates a dynamic library (libbit.so) in the build directory with this rule:
$(TARGET): $(OBJ)
$(CC) $(CFLAGS) -shared -o $@ $^ $(LDFLAGS)
Pros:
- Runtime binding, reducing memory footprint
- Updates to the library don't require recompiling Perl code
- Already implemented in your build system
- Better for distributing the library separately from the wrapper
Cons:
- Deployment requires ensuring the library is in the system path
- Potential version compatibility issues
2. Static Library Approach
To compile as a static library, you would modify the Makefile:
TARGET = $(BUILD_DIR)/libbit.a
$(TARGET): $(OBJ)
ar rcs $@ $^
Pros:
- Self-contained distribution
- No runtime dependency resolution
- Potentially faster function calls
- No path issues during deployment
Cons:
- Larger binary size
- Need to recompile wrapper if library changes
- Less memory efficient if multiple programs use the library
B. Perl Interfacing Options
1. SWIG
Pros:
- Automated wrapper generation
- Supports multiple languages (future portability)
- Good for complex interfaces
Cons:
- Learning curve for SWIG interface files
- Additional build dependency
- Complex for beginners
2. FFI::Platypus
Pros:
- No compilation required at installation time
- Modern, actively maintained
- Cleaner code than XS
- Suitable for your library structure
Cons:
- Requires FFI::Platypus and related modules
- Less efficient for very complex interfaces
3. Inline::C
Pros:
- Simple integration of C code directly in Perl
- No separate interface files
- Good for prototyping
Cons:
- C compiler required at runtime
- Less suitable for large libraries
- Performance overhead for initialization
4. XS
Pros:
- Standard Perl way to interface with C
- Excellent performance
- Tight integration with Perl's memory management
Cons:
- Steep learning curve
- Verbose, low-level coding
- More complex build process
Recommendation for Each Level
Beginner Level: FFI::Platypus with Dynamic Library
FFI::Platypus provides the easiest approach for beginners with minimal C knowledge. It works with your existing dynamic library build.
Intermediate Level: Inline::C with Dynamic Library
Inline::C offers more control for intermediate users who understand some C code but want to avoid complex build processes.
Advanced Level: XS with Static Library
XS provides the highest performance and greatest control, suitable for experienced Perl programmers.
Implementation for Beginner Level: FFI::Platypus
Let's create the Alien::Bit module first to handle library discovery, then implement Bit::Set and Bit::Set::DB modules using FFI::Platypus.
Step 1: Create Alien::Bit module
# /media/chrisarg/Software-Dev/Bit/perl-wrapper/lib/Alien/Bit.pm
package Alien::Bit;
use strict;
use warnings;
use parent 'Alien::Base';
use File::Spec;
sub dynamic_libs {
my $class = shift;
# Try to find the library in common locations
my @potential_paths = (
# From the build directory
'/media/chrisarg/Software-Dev/Bit/bit/build/libbit.so',
# System paths
'/usr/local/lib/libbit.so',
'/usr/lib/libbit.so',
# Environment variable if set
$ENV{BIT_LIB_PATH} ? File::Spec->catfile($ENV{BIT_LIB_PATH}, 'libbit.so') : ()
);
foreach my $path (@potential_paths) {
return $path if -f $path && -r $path;
}
die "Could not find libbit.so library. Please set BIT_LIB_PATH environment variable to its location.\n";
}
sub include_dirs {
return (
'/media/chrisarg/Software-Dev/Bit/bit/include',
'/usr/local/include',
'/usr/include',
$ENV{BIT_INCLUDE_PATH} || ()
);
}
1;
Step 2: Create Bit::Set module for individual bitsets
# /media/chrisarg/Software-Dev/Bit/perl-wrapper/lib/Bit/Set.pm
package Bit::Set;
use strict;
use warnings;
use FFI::Platypus;
use FFI::Platypus::Memory qw(malloc free);
use FFI::Platypus::Buffer qw(scalar_to_buffer buffer_to_scalar);
use Alien::Bit;
# Create FFI::Platypus object
my $ffi = FFI::Platypus->new(api => 1);
# Add path to our dynamic library
$ffi->lib(Alien::Bit->dynamic_libs);
# Define opaque types for our bitset pointers
$ffi->type('opaque' => 'Bit_T');
$ffi->type('opaque*' => 'Bit_T_Ptr');
# Define our Bit_T functions
$ffi->attach(Bit_new => ['int'] => 'Bit_T' => sub {
my ($xsub, $self, $length) = @_;
die "Length must be a positive integer" unless defined $length && $length > 0;
my $bit_set = $xsub->($length);
die "Failed to create bit set" unless $bit_set;
return bless { _handle => $bit_set }, $self;
});
$ffi->attach(Bit_free => ['Bit_T_Ptr'] => 'opaque' => sub {
my ($xsub, $self) = @_;
my $ptr = \$self->{_handle};
return $xsub->($ptr);
});
$ffi->attach(Bit_length => ['Bit_T'] => 'int' => sub {
my ($xsub, $self) = @_;
return $xsub->($self->{_handle});
});
$ffi->attach(Bit_count => ['Bit_T'] => 'int' => sub {
my ($xsub, $self) = @_;
return $xsub->($self->{_handle});
});
$ffi->attach(Bit_buffer_size => ['int'] => 'int');
$ffi->attach(Bit_bset => ['Bit_T', 'int'] => 'void' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
$xsub->($self->{_handle}, $index);
});
$ffi->attach(Bit_bclear => ['Bit_T', 'int'] => 'void' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
$xsub->($self->{_handle}, $index);
});
$ffi->attach(Bit_get => ['Bit_T', 'int'] => 'int' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
return $xsub->($self->{_handle}, $index);
});
$ffi->attach(Bit_set => ['Bit_T', 'int', 'int'] => 'void' => sub {
my ($xsub, $self, $lo, $hi) = @_;
die "Low index must be non-negative" unless defined $lo && $lo >= 0;
die "High index must be greater than or equal to low index" unless defined $hi && $hi >= $lo;
$xsub->($self->{_handle}, $lo, $hi);
});
$ffi->attach(Bit_clear => ['Bit_T', 'int', 'int'] => 'void' => sub {
my ($xsub, $self, $lo, $hi) = @_;
die "Low index must be non-negative" unless defined $lo && $lo >= 0;
die "High index must be greater than or equal to low index" unless defined $hi && $hi >= $lo;
$xsub->($self->{_handle}, $lo, $hi);
});
# Comparison operations
$ffi->attach(Bit_eq => ['Bit_T', 'Bit_T'] => 'int' => sub {
my ($xsub, $self, $other) = @_;
die "Other bitset must be a Bit::Set object" unless ref $other eq ref $self;
return $xsub->($self->{_handle}, $other->{_handle});
});
# Set operations
$ffi->attach(Bit_union => ['Bit_T', 'Bit_T'] => 'Bit_T' => sub {
my ($xsub, $self, $other) = @_;
die "Other bitset must be a Bit::Set object" unless ref $other eq ref $self;
my $result_handle = $xsub->($self->{_handle}, $other->{_handle});
return bless { _handle => $result_handle }, ref $self;
});
$ffi->attach(Bit_inter => ['Bit_T', 'Bit_T'] => 'Bit_T' => sub {
my ($xsub, $self, $other) = @_;
die "Other bitset must be a Bit::Set object" unless ref $other eq ref $self;
my $result_handle = $xsub->($self->{_handle}, $other->{_handle});
return bless { _handle => $result_handle }, ref $self;
});
# Count operations
$ffi->attach(Bit_inter_count => ['Bit_T', 'Bit_T'] => 'int' => sub {
my ($xsub, $self, $other) = @_;
die "Other bitset must be a Bit::Set object" unless ref $other eq ref $self;
return $xsub->($self->{_handle}, $other->{_handle});
});
# Constructor and destructor
sub new {
my ($class, $length) = @_;
return $class->Bit_new($length);
}
sub DESTROY {
my ($self) = @_;
$self->Bit_free() if defined $self->{_handle};
}
# Convenient accessor methods
sub length {
my ($self) = @_;
return $self->Bit_length();
}
sub count {
my ($self) = @_;
return $self->Bit_count();
}
sub get {
my ($self, $index) = @_;
return $self->Bit_get($index);
}
sub set {
my ($self, $index) = @_;
$self->Bit_bset($index);
return $self;
}
sub clear {
my ($self, $index) = @_;
$self->Bit_bclear($index);
return $self;
}
sub set_range {
my ($self, $lo, $hi) = @_;
$self->Bit_set($lo, $hi);
return $self;
}
sub clear_range {
my ($self, $lo, $hi) = @_;
$self->Bit_clear($lo, $hi);
return $self;
}
sub equals {
my ($self, $other) = @_;
return $self->Bit_eq($other) ? 1 : 0;
}
sub union {
my ($self, $other) = @_;
return $self->Bit_union($other);
}
sub intersection {
my ($self, $other) = @_;
return $self->Bit_inter($other);
}
sub intersection_count {
my ($self, $other) = @_;
return $self->Bit_inter_count($other);
}
1;
Step 3: Create Bit::Set::DB module for packed containers
# /media/chrisarg/Software-Dev/Bit/perl-wrapper/lib/Bit/Set/DB.pm
package Bit::Set::DB;
use strict;
use warnings;
use FFI::Platypus;
use FFI::Platypus::Memory qw(malloc free);
use FFI::Platypus::Buffer qw(scalar_to_buffer buffer_to_scalar);
use Bit::Set;
use Alien::Bit;
# Create FFI::Platypus object
my $ffi = FFI::Platypus->new(api => 1);
# Add path to our dynamic library
$ffi->lib(Alien::Bit->dynamic_libs);
# Define opaque types for our bitset pointers
$ffi->type('opaque' => 'Bit_T');
$ffi->type('opaque' => 'Bit_T_DB');
$ffi->type('opaque*' => 'Bit_T_DB_Ptr');
# Define struct for SETOP_COUNT_OPTS
$ffi->type('record(SETOP_COUNT_OPTS)' => [
num_cpu_threads => 'int',
device_id => 'int',
upd_1st_operand => 'bool',
upd_2nd_operand => 'bool',
release_1st_operand => 'bool',
release_2nd_operand => 'bool',
release_counts => 'bool'
]);
# Define Bit_T_DB functions
$ffi->attach(BitDB_new => ['int', 'int'] => 'Bit_T_DB' => sub {
my ($xsub, $self, $length, $num_of_bitsets) = @_;
die "Length must be a positive integer" unless defined $length && $length > 0;
die "Number of bitsets must be a positive integer" unless defined $num_of_bitsets && $num_of_bitsets > 0;
my $db = $xsub->($length, $num_of_bitsets);
die "Failed to create bitset DB" unless $db;
return bless { _handle => $db }, $self;
});
$ffi->attach(BitDB_free => ['Bit_T_DB_Ptr'] => 'opaque' => sub {
my ($xsub, $self) = @_;
my $ptr = \$self->{_handle};
return $xsub->($ptr);
});
$ffi->attach(BitDB_length => ['Bit_T_DB'] => 'int' => sub {
my ($xsub, $self) = @_;
return $xsub->($self->{_handle});
});
$ffi->attach(BitDB_nelem => ['Bit_T_DB'] => 'int' => sub {
my ($xsub, $self) = @_;
return $xsub->($self->{_handle});
});
$ffi->attach(BitDB_count_at => ['Bit_T_DB', 'int'] => 'int' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
return $xsub->($self->{_handle}, $index);
});
$ffi->attach(BitDB_clear => ['Bit_T_DB'] => 'void' => sub {
my ($xsub, $self) = @_;
$xsub->($self->{_handle});
});
$ffi->attach(BitDB_clear_at => ['Bit_T_DB', 'int'] => 'void' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
$xsub->($self->{_handle}, $index);
});
$ffi->attach(BitDB_get_from => ['Bit_T_DB', 'int'] => 'Bit_T' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
my $bit_handle = $xsub->($self->{_handle}, $index);
return bless { _handle => $bit_handle }, 'Bit::Set';
});
$ffi->attach(BitDB_put_at => ['Bit_T_DB', 'int', 'Bit_T'] => 'void' => sub {
my ($xsub, $self, $index, $bitset) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
die "Bitset must be a Bit::Set object" unless ref $bitset eq 'Bit::Set';
$xsub->($self->{_handle}, $index, $bitset->{_handle});
});
# CPU-specific intersection count function
$ffi->attach(BitDB_inter_count_cpu => ['Bit_T_DB', 'Bit_T_DB', 'SETOP_COUNT_OPTS'] => 'int*' => sub {
my ($xsub, $self, $other, $opts) = @_;
die "Other must be a Bit::Set::DB object" unless ref $other eq ref $self;
$opts ||= {
num_cpu_threads => 1,
device_id => -1,
upd_1st_operand => 0,
upd_2nd_operand => 0,
release_1st_operand => 0,
release_2nd_operand => 0,
release_counts => 0
};
return $xsub->($self->{_handle}, $other->{_handle}, $opts);
});
# Constructor and destructor
sub new {
my ($class, $length, $num_of_bitsets) = @_;
return $class->BitDB_new($length, $num_of_bitsets);
}
sub DESTROY {
my ($self) = @_;
$self->BitDB_free() if defined $self->{_handle};
}
# Convenient accessor methods
sub length {
my ($self) = @_;
return $self->BitDB_length();
}
sub num_of_bitsets {
my ($self) = @_;
return $self->BitDB_nelem();
}
sub count_at {
my ($self, $index) = @_;
return $self->BitDB_count_at($index);
}
sub clear {
my ($self) = @_;
$self->BitDB_clear();
return $self;
}
sub clear_at {
my ($self, $index) = @_;
$self->BitDB_clear_at($index);
return $self;
}
sub get_bitset {
my ($self, $index) = @_;
return $self->BitDB_get_from($index);
}
sub put_bitset {
my ($self, $index, $bitset) = @_;
$self->BitDB_put_at($index, $bitset);
return $self;
}
sub intersection_count_cpu {
my ($self, $other, $opts) = @_;
return $self->BitDB_inter_count_cpu($other, $opts);
}
1;
Step 4: Example usage script
#!/usr/bin/perl
use strict;
use warnings;
use Bit::Set;
use Bit::Set::DB;
# Create a new bitset with 1024 bits
my $bitset1 = Bit::Set->new(1024);
my $bitset2 = Bit::Set->new(1024);
# Set some bits
$bitset1->set(42);
$bitset1->set(100);
$bitset2->set(42);
$bitset2->set(200);
# Check if a bit is set
print "Bit 42 in bitset1: ", $bitset1->get(42), "\n";
print "Bit 100 in bitset1: ", $bitset1->get(100), "\n";
print "Bit 200 in bitset1: ", $bitset1->get(200), "\n";
# Count the number of bits set
print "Number of bits set in bitset1: ", $bitset1->count(), "\n";
print "Number of bits set in bitset2: ", $bitset2->count(), "\n";
# Calculate intersection count
my $intersection_count = $bitset1->intersection_count($bitset2);
print "Intersection count: $intersection_count\n";
# Create a new bitset as the union of the two bitsets
my $union = $bitset1->union($bitset2);
print "Number of bits set in union: ", $union->count(), "\n";
# Create a BitDB with 3 bitsets of length 1024
my $db = Bit::Set::DB->new(1024, 3);
# Put our bitsets into the DB
$db->put_bitset(0, $bitset1);
$db->put_bitset(1, $bitset2);
$db->put_bitset(2, $union);
# Count bits in each bitset in the DB
print "Bits set in DB at index 0: ", $db->count_at(0), "\n";
print "Bits set in DB at index 1: ", $db->count_at(1), "\n";
print "Bits set in DB at index 2: ", $db->count_at(2), "\n";
Modifications for Intermediate Level (Inline::C)
For intermediate-level Perl programmers, here are the changes required to implement the wrapper using Inline::C:
# Bit::Set using Inline::C
package Bit::Set;
use strict;
use warnings;
use Inline C => Config =>
BUILD_NOISY => 1,
CLEAN_AFTER_BUILD => 0,
LIBS => '-L/media/chrisarg/Software-Dev/Bit/bit/build -lbit',
INC => '-I/media/chrisarg/Software-Dev/Bit/bit/include';
use Inline C => <<'END_C';
#include "bit.h"
typedef struct Bit_T* Bit_T;
// Wrapper functions
Bit_T create_bitset(int length) {
return Bit_new(length);
}
void free_bitset(Bit_T set) {
Bit_free(&set);
}
int get_length(Bit_T set) {
return Bit_length(set);
}
int get_count(Bit_T set) {
return Bit_count(set);
}
void set_bit(Bit_T set, int index) {
Bit_bset(set, index);
}
void clear_bit(Bit_T set, int index) {
Bit_bclear(set, index);
}
int get_bit(Bit_T set, int index) {
return Bit_get(set, index);
}
// Add more wrapper functions as needed
END_C
# Perl OO interface
sub new {
my ($class, $length) = @_;
my $handle = create_bitset($length);
return bless { _handle => $handle }, $class;
}
# Add more methods similar to the FFI version
Modifications for Advanced Level (XS)
For advanced Perl programmers, here are the key changes required to implement using XS:
# Bit::Set.xs
#include "EXTERN.h"
#include "perl.h"
#include "XSUB.h"
#include "bit.h"
typedef struct Bit_T* Bit_T;
typedef struct Bit_T_DB* Bit_T_DB;
MODULE = Bit::Set PACKAGE = Bit::Set
PROTOTYPES: DISABLE
Bit_T
Bit_new(length)
int length
void
Bit_free(set)
Bit_T set
CODE:
Bit_free(&set);
int
Bit_length(set)
Bit_T set
int
Bit_count(set)
Bit_T set
void
Bit_bset(set, index)
Bit_T set
int index
# Add more functions as needed
And update the Makefile.PL:
use ExtUtils::MakeMaker;
WriteMakefile(
NAME => 'Bit::Set',
VERSION_FROM => 'lib/Bit/Set.pm',
LIBS => ['-L/media/chrisarg/Software-Dev/Bit/bit/build -lbit'],
INC => '-I/media/chrisarg/Software-Dev/Bit/bit/include',
OBJECT => '$(O_FILES)',
);
Conclusion
For most users, especially beginners, the FFI::Platypus approach offers the best balance of simplicity,
performance, and maintainability. It works well with your existing dynamic library build process and
provides a clean, object-oriented interface to the Bit_T and Bit_T_DB types. The implementation provided
covers all the core functionality while being extensible for additional features as needed.
My critique of Claude's choices
In this first post, we will not consider the implementation(s) which will be covered in separate posts, but will restrict ourselves to Claude's output with respect to the other questions. I give Claude bonus points for clearly identifying the niches for each potential choice:
- Highighting that SWIG can support wrapping for other languages)
- Proposing Foreign Function Interface for linking to the dynamic library for beginners.
- A experienced programmer would opt for XS is not a surprise at all.
However:
- the choice of Inline for the intermediate user is head-scratching: it seems that the chatbot closed on the intermediate level of programming experience in the prompt, and the selection of the approach was driven entirely by the fact that the user could (presumably) do more stuff in C.
- SWIG was not considered as suitable (perhaps because few people in the training databases use SWIG) for implementing at any level. Without going into the specifics of the implementation though, I'd feel comfortable opting for FFI as an initial step for largely the reasons identified by Claude. We will have more things to say about the FFI implementation in the subsequent post in this series.
Note, I did not use the word understanding, as I do not think that LLMs can understant: they are merely noisy statistical pattern generators that can be tasked to create rough solutions for refining.
I alerted the bot to the (substantial) risk of hallucinations and decreased
rjbs in Rio, part ⅰ
rjbs forgot what he was sayingPublished by Ricardo Signes on Monday 30 June 2025 12:00
So, I went to Rio de Janeiro! It was great, and it’ll probably take me several entries to sufficiently cover the trip. Here we go!
Background
The background for this trip is worth mentioning. For years, I’ve been seeing my friend Breno at the annual Perl Toolchain Summit. He was also a regular in an online D&D game I ran. All the time, he’d say, “Look, man, you’ve gotta come visit Brazil. It’d be so great!” I would say, “I bet it would, but I really mostly travel where work sends me, and I can’t see a work trip to Brazil happening any time in the near future.”
Then, early last year, I got an email from a frequent flyer program telling me that if I didn’t use my reward miles, I’d lose them. I managed to not lose them immediately, but it seemed like this was a sign. I tried to think of where I might go, and I remembered all of Breno’s exhortations. I looked it up, and I could definitely get to Rio and back on miles. I emailed him and said, “Okay, when would be good?” He wrote back with a long enthusiastic analysis of the year, including this:
The Festas Juninas are probably less known outside Brazil but also very typical and popular, happening all over the country in June/July, usually in the afternoon or at dusk. it’s less crowded and “partyesque” but there is dancing and fire and costumes and very typical food and drinks that are harder to find the rest of the year.
Sounded perfect! I decided to make plans.
Getting there
Over the course of the next year, this went from vague idea to definite plan, and I started to put together a list of things I’d like to see or do. I read a lot of “what you must see in Rio” pages, plus ones that covered more obscure topics. I asked Breno and Barbara (Breno’s wife, also a friend) to tell me whether my list was any good. By the time the trip was upon me, I had what felt like a great set of things to do. Even better, Barbara provided a suggested day-by-day agenda, which would’ve been a pain for me. It included a bunch of “and then we’ll take you to something we think is really worth it.” Who could ask for more?
Meanwhile, though, the articles I read kept saying, “You’re going to love Rio! It’s so wonderful! You are definitely at high risk of getting mugged, though!” Mostly I shrug this stuff off. I live in Philly, and I’m used to people talking about my home like it’s a warzone. Still, I got a little anxious. Breno reassured me, I decided to keep my phone in my purse, and I tried to put aside any fears. Then, on the 18th, I got my bag and headed to the airport. It was going to be a bit of a long trip, but I’m used to going to Australia. This would be no big deal.
Really, it mostly wasn’t. The only complication was that instead of a 6 hour layover between flights, I had a 6 hour layover plus a 16 hour delay. It was mostly overnight, so I didn’t get to tool around Miami. I mostly sat around the lounge and the Holiday Inn and watched TV. It was fine, but I didn’t love losing a day.
Eventually, I landed at GIG. (Did you know that Rio’s international airport is named after the guy who wrote The Girl from Ipanema? It is!). Instead of landing at 8:00 in the morning, I landed around 1:00 in the morning, and then I had to get through immigration and customs and find a cab. Then the cab got pulled over by the police, who ordered me out of the car at gunpoint and searched all my stuff. Honestly, I might have been more nervous if I wasn’t so tired.
Thursday
I feel a bit badly about beginning my trip story this way, but it’s how it began. The good news (spoilers!) is that it was the only remotely worrying event of my trip, and I wan’t even really worried at any point. We were let go pretty quickly, and then I was in my apartment and asleep. The next day, I was on the beach and everything was good.

My first day was supposed to be Wednesday, which I would’ve spent exploring the beaches and maybe finding one of the nearby art museums, but that was shot. It was Thursday, and that meant lunch with Breno and Babs and their daughter. We had “angu”, which I’d describe as something like a polenta-and-offal stew. It was great, right up my alley!

Then it was on to the Museum of Tomorrow (the architecture was great, but we mostly coasted through the exhibits), and then São Cristóvão Fair, which I later described as “what if Philly’s Reading Terminal Market was in Brazil and had three competing live music acts at all times”. It was great, although a little loud. We had a bunch more delicious food (lots of photos on Flickr), and I had my second caipirinha of the day. If I have one regret of the trip, it’s not drinking more of those. I suspect it’ll be hard to find or make a good one at home, but we’ll see.
A caipirinha is a bit like a daquiri. It’s made with cachaça, which is a bit like white rum. Then sugar, lime, and ice. It seems like the drink of Brazil, or at least Rio. (Brazil is huge. If you sort of vaguely agree that Brazil isn’t very small, go look it up. It’s the fifth largest country in the world, smaller than the USA and larger than Australia. I don’t want to get accused of saying something like “the mint julep is the drink of the US”.) Anyway, I had probably four or five across the trip, and I could’ve done with more like eight.
The music at the fair was foreshadowing. There was lots of live music all over the place, and it didn’t seem like a tourist gimmick. It was always pretty upbeat, and everybody sang along and danced with everything. “Oh, this is a very famous song,” was definitely one of the things Breno said to me the most.
Also notable: the ice cream. Breno pointed at the menu – and I’m sorry to say I didn’t get a photo! “On the right,” he said, “are all the boring flavors you know. Chocolate, vanilla, mint. Who cares? On the left, though, it’s all fruit flavors, and I won’t bother translating, because you don’t have words in English for any of these. They’re all South American fruits.” I had jaboticaba. The ice cream was very good, but the exciting thing was this list of weird fruits that I’d never heard of. Weirder, jaboticaba fruit grow right on the trunk of the tree? Just weird.
There was at least one fruit on the list that I did know: pineapple. I was surprised and pleased to learn, though, that in Brazil they don’t call pineapple ananás, as they do in Portugal and nearly everywhere else. They call it abacaxi. Rejecting the worldwide standard name for that fruit made the people of Brazil seem even more like my brothers and sisters. Too bad they still use the metric system.

After the fair, Breno dropped me off at my apartment. There’s only an hour of time difference from home to Rio, but I was beat. I wasn’t ready to collapse into sleep, but I was no good for any kind of conversation by the end of the night. I zoned out and eventually crashed.
Friday
Friday was my first day on my own, and I had a plan: Sugarloaf! Sugarloaf Mountain is a 1300’ mountain at the mouth of Rio’s bay. It’s called Sugarloaf because it looks like a sugarloaf. A sugarloaf is how sugar was sold for hundreds of years, well until the 19th century, so I guess at one point it was pretty useful to say “it’s that mountain that looks like a sugarloaf!” Now, I think of a sugarloaf as “a compressed hunk of sugar shaped like that mountain in Rio”.
I knew the mountain would have a good view of the city and the bay, but I was mostly in it for the cable car ride. I’m not sure why, since I’m not a huge lover of heights, but it seemed pretty compelling. Before I came down, Breno had said, “the cable car! Like in Moonraker!” I had never watched Moonraker, so I watched it on the flight down. I don’t recommend it. On the other hand, the cable car ride was great. Happily, the mountain was even better than that!
I’d hoped to ride up in the mid-afternoon so that I could ride down during sunset. In retrospect, I think I could’ve made that work, but it wasn’t a clear win at the time. I hadn’t been able to buy tickets online, so I’d have to go out to the mountain and hope to get timed entry tickets for a reasonable time. I didn’t want to get there only to find out that I couldn’t get tickets, so I ended up going early. I wasn’t disappointed, and honestly I’m not sure I’d have been any happier with sunset.
The cable car actually goes to two mountains. First, to Urca Hill, then Sugarloaf Mountain. It’s two separate cable car rides, and you can spend as much time as you want on Urca Hill between them. I spent a few hours, and it was great. There was food (I had corn, a sausage sandwich, ice cream, and later a beer), there were crafts, and there were amazing views in every direction. When I couldn’t appreciate the view any more, I sat down and read a book for ten minutes, then got back to the view. It was excellent.

That view above is actually from Urca Hill. In the distance, you can see Corcovado (“the hunchback”), the mountain on which Rio’s giant Christ the Redeemer statue stands. It was visible from all over the city, and I saw it up close and personal later in the trip. This was one of the cooler views of it, though.
From Urca Hill, I took the second cable car to Sugarloaf. It was very cool, and I think the views were marginally better, but it was much more crowded-feeling in that smaller space, and the food and shops weren’t inviting. I didn’t stay up there half as long as I was on Urca Hill. In fact, when I got back to Urca Hill I spend more time there, getting an ice cream cone and doing some people-watching.
After that, I was ready for a break. I got back to my apartment, zoned out for a little bit, and then hit the grocery. I picked up OJ, eggs, bread, and tea, which meant that I could start every day with a little breakfast. That meant I wouldn’t be hungry until dinner, most days, if I kept busy, which made every day easier. I also picked up a packet of Globo biscuits, which are a sort of flavorless cassava-based Funyun. They were everywhere, in Rio, but also had nothing much to recommend them other than the crunchiness.
I also also picked up some iced mate tea, which I enjoyed drinking most days. I think I’m going to see if I can get any tea leaves for making it at home, but we’ll see.
After I’d relaxed for a while, I headed to Arpoador, the peninsula between the Ipanema and Copacabana beaches. There’s a big rock there (Arpoador Rock), which some people say is the best place in the world to see the sunset. I was skeptical, but it was very good. The rock was swarming with people, but I managed to find a place to watch the sun set. There are lots more photos in my trip album, but here’s one:

After that, I walked slowly back to my apartment. I stopped at two concerts, both of which were great, and I had a Brahma beer, which was good, especially for the weather. I didn’t get to try many Brazilian beers, but I enjoyed this one. Looking back, I wish I’d bought one more beer to drink on the walk. I should try to enjoy “walk with a beer” time when traveling to places where that’s legal.
Eventually, I made it back to my apartment and turned in. More on the rest of the trip in future posts!
Perl 🐪 Weekly #727 - Which versions of Perl do you use?
dev.to #perlPublished by Gabor Szabo on Monday 30 June 2025 05:45
Originally published at Perl Weekly 727
Hi there!
Recently I ran a poll asking Which versions of Perl do you use at work?. I asked it both in the The Perl Community group on Facebook and in the Perl Maven community Telegram Channel and the Perl 5 Telegram channel.
There were 75 votes in the Facebook group: 1% use 5.42; 17% use 5.40; 30% use 5.38; 5% use 5.36; 29% use 5.22-5.34; 13% use 5.12-5.20; 5% use 5.10 or older.
There were 29 votes in the Telegram group(s): 14% use 5.42; 31% use 5.40; 34% use 5.38; 7% use 5.36; 38% use 5.22-5.34; 17% use 5.12-5.20; 7% use 5.10 or older. Yes, people could select multiple answers.
You can still go an vote in either of those polls.
Many people commented that they use the version of perl that comes with the OS, to which Dave Cross posed Stop using your system Perl. I don't fully agree, but he has a point.
I don't recall what exactly prompted me to do this, but a few days ago I started to write a book about OOP - Object Oriented Perl. I took some of the slides I had for my advanced Perl course, started to update them and started to write explanations around the examples. As I write them I post the articles in the Perl Community group on Facebook and on my LinkedIn page. If you use Facebook I'd recommend you join that group and if you use LinkedIn I'd recommend you follow me. If you would like to go further and connect with me on LinkedIn, please include a message saying that you are a reader of the Perl Weekly newsletter so I'll have some background.
Besides publishing them on the social sites I also collect the writings about Perl OOP on my web site and I also started to publish the book on Leanpub.
As I am sure you know editing the Perl weekly, writing these examples and articles and the book takes a lot of time that I should spend earning money by helping my clients with their Perl code-base. Luckily there are some people who support me financially via Patreon, GitHub. (Hint: it would be awesome if you'd also sponsor me with $10/month.)
There are many people who like to get something 'tangible' to really justify their support. If you are such a person I created the Leanpub book especially for you. You can buy the Perl OOP book and some of my other books getting a pdf and an epub (for Kindle) version. You will both support my work and get an e-book. You will also get all the new versions of the book as I update it.
Enjoy your week!
--
Your editor: Gabor Szabo.
Articles
Stop using your system Perl
For years Dave has been telling us to use our own version of Perl and not to rely on the one that comes with our version of the Operating System. There is a lot of merit in what he is say and what he is writing in this article. I personally would go to the most extreme and use a Docker container for better separation and to make the development, testing, and production environments as similar as possible. With that said I am not 100% sold on the idea. I do understand the value in using the perl that comes with the OS and the perl modules that can be installed with the package-management system of the operating system. (e.g. apt/yum). See an extensive discussion on the topic.
Analysing FIT data with Perl: producing PNG plots
FIT files record the activities of people using devices such as sports watches and bike head units.
Lexical Method in Perl v5.42
There are all kinds of new and nice ways to write Perl code. Reading this article you'll learn about the new, experimental 'class' feature a bit more.
AWS DynamoDB
AWS DynamoDB is a fully managed NoSQL database service provided by AWS.
Discussion
Is there a (standardized) way to declare dependencies to a directory in a cpanfile?
How do you manage the dependencies of a Perl module that depends on another perl module (distribution) developed in the same monorepo?
Is there a tool that solves the constraint problem for Perl packages?
What happens when the same module is required both by your code and by one of your dependencies? Which version of that shared dependency will be installed?
Jobs
Where Are All the Perl Jobs in 2025?
Just a few days ago I asked on our Telegram channel which companies use Perl for application development and now I see this post. Apparently there is a new web-site listing 'Perl jobs'. I don't know who is behind that site, but the background image has 'use strict' and 'use warnings' so it isn't that bad.
How to find Perl job in 2025?
A discussion with some good (and some bad) suggestions there.
Full Stack Developer with strong Perl expertise
Perl Developer
Perl
This week in PSC (196) | 2025-06-19
The Weekly Challenge
The Weekly Challenge by Mohammad Sajid Anwar will help you step out of your comfort-zone. You can even win prize money of $50 by participating in the weekly challenge. We pick one champion at the end of the month from among all of the contributors during the month, thanks to the sponsor Lance Wicks.
The Weekly Challenge - 328
Welcome to a new week with a couple of fun tasks "Replace all ?" and "Good String". If you are new to the weekly challenge then why not join us and have fun every week. For more information, please read the FAQ.
RECAP - The Weekly Challenge - 327
Enjoy a quick recap of last week's contributions by Team PWC dealing with the "Missing Integers" and "MAD" tasks in Perl and Raku. You will find plenty of solutions to keep you busy.
Missing Integers Don’t Make Me MAD, Just Disappointed
Taking advantage of Perl's hash lookup speed, O(1) time complexity. Keeps the implementation readable and concise.
TWC327
A compact, correct, and Perl-savvy solution sets. The post’s minimalist style reflects a strong grasp of both Perl idioms and the challenge requirements.
Missing Mad
A well-structured, educational post that highlights the expressive power of Raku while staying true to challenge constraints. The inclusion of verbose output, clean modularity, and idiomatic constructs makes it an excellent read for both Raku learners and seasoned scripters.
Perl Weekly Challenge: Week 327
Offers elegant solutions in Raku and also provides working Perl equivalents. It balances code with commentary.
Absolutely Missing Differences
A technically sharp, creative post—especially with the use of PDL.
Perl Weekly Challenge 327
Practical, ready-to-run code with clear explanation and includes both straightforward Perl and more advanced PDL solutions.
Missing and Mad
It provides concise and elegant solutions to both challenges with clear explanations of the reasoning behind them. The use of idiomatic Perl (e.g., map, grep, keys, and smart use of hashes) is idiomatic and effective.
Missing Absolute Distance
It demonstrates good teaching style by explaining the problem, providing example inputs/outputs, and showing step-by-step approaches. The inclusion of multiple languages (Raku, Perl, Python, Elixir) is very valuable for readers interested in cross-language algorithm implementations.
Missing and mad
Both solutions are clean, efficient, and well-documented. It prioritises readability over one-liners—a good choice for maintainability.
The Weekly Challenge #327
Using none to check if a number is missing is idiomatic and easy to read. Setting $"=', ' for array printing is a good touch.
I Miss My Mind the Most
Away week, still got Rust for us. As always, a detailed and descriptive approach makes the reading fun.
The weekly challenge 327
This post is a well-written, thoughtful exploration of two classic array problems, each solved elegantly in both Python and Perl, with a particular focus on bitarray usage and iteration techniques.
Perl Tutorial
A section for newbies and for people who need some refreshing of their Perl knowledge. If you have questions or suggestions about the articles, let me know and I'll try to make the necessary changes. The included articles are from the Perl Maven Tutorial and are part of the Perl Maven eBook.
Videos
GPW 2025 - Mark Overmeer - Mid-life upgrade for MailBox
Weekly collections
NICEPERL's lists
Great CPAN modules released last week.
Events
Purdue Perl Mongers - TBA
July 9, 2025
You joined the Perl Weekly to get weekly e-mails about the Perl programming language and related topics.
Want to see more? See the archives of all the issues.
Not yet subscribed to the newsletter? Join us free of charge!
(C) Copyright Gabor Szabo
The articles are copyright the respective authors.
Vibe coding a Perl interface to a foreign library- Part 1
Killing-It-with-PERLPublished on Monday 30 June 2025 00:00
Introduction
In this multipart series we will explore the benefits (and pitfalls) of vibe coding a Perl interface to an external (or foreign) library through a large language model. Those of you who follow me on X/Twitter (as @ChristosArgyrop and @ArgyropChristos), Bluesky , mast.hpc, mstdn.science, mstdn.social know that I have been very critical of the hype behind AI and the hallucinations of both models and the human AI influencers (informally known as botlickers in some corners of the web).
However, there are application areas of vibe coding with AI, e.g. semi-automating the task of creating API from one one language to another, in which the chatbots may actually deliver well and act as productivity boosters. In this application area, we will be leveraging the AI tools as more or less enhanced auto-complete tools that can help a developer navigate less familiar, more technical and possibly more boring aspects of the target language’s ‘guts’. If AI were to deliver in this area, then meaningless language wars can be averted, and wrong (at least in my opinion) reasons to prefer one language, i.e. the availability of some exotic library, may be avoided.
For my foray in this area, I chose to interface to the library Bit that I wrote to support text fingerprinting for some research applications. The library based on David Hanson’s Bit_T library discussed in Chapter 13 of “C Interfaces and Implementations” has been extended to incorporate additional operations on bitsets (such as counts on unions/differences/intersections of sets) and fast population counts in both CPU and GPU (with TPU implementations coming down the road). Hence, this is a test case that can illustrate the utility of Perl in using code that executes transparently in various hardware assets. Similar to Hanson’s original implementation (after all, my work is based on his!) the library interface is implemented to an Abstract Data Type in C; a crucial aspect of the implementation is to manage memory and avoid leaks without looking (at all, or as little as possible!) under the hood. For our experiments we will use Claude 3.7 Thinking Sonnet through the Github Copilot vscode interface. This is going to be a multipart series post that will be published throughout the summer. Our focus will be on interactions between me and the bot, and in particular critiquing the responses it has given me for both high level (e.g. choice of approach) and technical aspects of the project.
The Prompt
For the prompt I provided the “bit.c”, “bit.h”, makefile and the readme file of the Bit github repository as context to Claude and then I issued the following:
Look at the bit.h file that defines two abstract data types Bit_T and Bit_T_DB
and their interfaces in C. I would like to wrap these interfaces in Perl.
The build process will consist of using the Alien package in Perl to make bit available to Perl.
Explore possible options for the creation of the interface:
A. Creation of the bit C library :
1) compiling bit.c and bit.h as dynamic libraries
2) compiling bit.c nd bit.h into a static library
B. Interfacing with the bit C library from Perl:
1) using SWIG i files
2) using Platypus::FFI
3) using Inline::C
4) using XS
Since you are an expert with deep knowledge of the Perl ecosystem, consider pros and cons of
each approach. and then recommend the optimal Consider lightweight options for encapsulating
the Bit_T and Bit_T_DB abstract data types as Perl objects.
Provide wrapping recommendations targetting a beginner, intermediate and experienced Perl
programmer since those may differ. When providing recommendations , consider the dependencies
that are required for each implementation and highlight them in your analysis.
Once you have provided the recommendation, provide the implementation of the wrapper for
these 3 programmer levels. To reduce the token output (and your risk of hallucinating),
provide a full implementation of the wrapper for the beginner level and only the
changes (if any) that are required for the intermediate and advanced programmer levels.
In my prompt specification, I clearly specified that
- linkage to the foreign library could be either as a static or a dynamic object,
- the desired way to package the dependency for use in Perl is an Alien package
- all four possible ways to interface to a foreign library from Perl should be considered.
- asked it to consider the problem of wrapping from the perspective of Perl developers with different levels of expertise.
Note that I gave the bot considerable freedom over the “low” level aspects of wrapping (type of library, choice of the cross-language interface), but restricted it in terms of how I wanted the library served. Furthermore, I guided it to consider alternative viewpoints and level of expertise, providing a unique opportunity to test Claude’s representation1 of conversations about wrappers. Finally, I alerted the chatbot to consider the token-sequence length dependent risk of hallucinations and tried to limit the length of the output of the alternative implementations.
Claude’s Response
The output based on this prompt is shown below (inside the horizontal lines); the formatting was also part of the output
Perl Wrapper for Bit_T and Bit_T_DB C Library
Let me analyze the options for creating a Perl interface to the Bit_T and Bit_T_DB C library and provide implementation recommendations for programmers at different experience levels.
A. Creation of the Bit C Library
1. Dynamic Library Approach
I see the Makefile already creates a dynamic library (libbit.so) in the build directory with this rule:
$(TARGET): $(OBJ)
$(CC) $(CFLAGS) -shared -o $@ $^ $(LDFLAGS)
Pros:
- Runtime binding, reducing memory footprint
- Updates to the library don’t require recompiling Perl code
- Already implemented in your build system
- Better for distributing the library separately from the wrapper
Cons:
- Deployment requires ensuring the library is in the system path
- Potential version compatibility issues
2. Static Library Approach
To compile as a static library, you would modify the Makefile:
TARGET = $(BUILD_DIR)/libbit.a
$(TARGET): $(OBJ)
ar rcs $@ $^
Pros:
- Self-contained distribution
- No runtime dependency resolution
- Potentially faster function calls
- No path issues during deployment
Cons:
- Larger binary size
- Need to recompile wrapper if library changes
- Less memory efficient if multiple programs use the library
B. Perl Interfacing Options
1. SWIG
Pros:
- Automated wrapper generation
- Supports multiple languages (future portability)
- Good for complex interfaces
Cons:
- Learning curve for SWIG interface files
- Additional build dependency
- Complex for beginners
2. FFI::Platypus
Pros:
- No compilation required at installation time
- Modern, actively maintained
- Cleaner code than XS
- Suitable for your library structure
Cons:
- Requires FFI::Platypus and related modules
- Less efficient for very complex interfaces
3. Inline::C
Pros:
- Simple integration of C code directly in Perl
- No separate interface files
- Good for prototyping
Cons:
- C compiler required at runtime
- Less suitable for large libraries
- Performance overhead for initialization
4. XS
Pros:
- Standard Perl way to interface with C
- Excellent performance
- Tight integration with Perl’s memory management
Cons:
- Steep learning curve
- Verbose, low-level coding
- More complex build process
Recommendation for Each Level
Beginner Level: FFI::Platypus with Dynamic Library
FFI::Platypus provides the easiest approach for beginners with minimal C knowledge. It works with your existing dynamic library build.
Intermediate Level: Inline::C with Dynamic Library
Inline::C offers more control for intermediate users who understand some C code but want to avoid complex build processes.
Advanced Level: XS with Static Library
XS provides the highest performance and greatest control, suitable for experienced Perl programmers.
Implementation for Beginner Level: FFI::Platypus
Let’s create the Alien::Bit module first to handle library discovery, then implement Bit::Set and Bit::Set::DB modules using FFI::Platypus.
Step 1: Create Alien::Bit module
# /media/chrisarg/Software-Dev/Bit/perl-wrapper/lib/Alien/Bit.pm
package Alien::Bit;
use strict;
use warnings;
use parent 'Alien::Base';
use File::Spec;
sub dynamic_libs {
my $class = shift;
# Try to find the library in common locations
my @potential_paths = (
# From the build directory
'/media/chrisarg/Software-Dev/Bit/bit/build/libbit.so',
# System paths
'/usr/local/lib/libbit.so',
'/usr/lib/libbit.so',
# Environment variable if set
$ENV{BIT_LIB_PATH} ? File::Spec->catfile($ENV{BIT_LIB_PATH}, 'libbit.so') : ()
);
foreach my $path (@potential_paths) {
return $path if -f $path && -r $path;
}
die "Could not find libbit.so library. Please set BIT_LIB_PATH environment variable to its location.\n";
}
sub include_dirs {
return (
'/media/chrisarg/Software-Dev/Bit/bit/include',
'/usr/local/include',
'/usr/include',
$ENV{BIT_INCLUDE_PATH} || ()
);
}
1;
Step 2: Create Bit::Set module for individual bitsets
# /media/chrisarg/Software-Dev/Bit/perl-wrapper/lib/Bit/Set.pm
package Bit::Set;
use strict;
use warnings;
use FFI::Platypus;
use FFI::Platypus::Memory qw(malloc free);
use FFI::Platypus::Buffer qw(scalar_to_buffer buffer_to_scalar);
use Alien::Bit;
# Create FFI::Platypus object
my $ffi = FFI::Platypus->new(api => 1);
# Add path to our dynamic library
$ffi->lib(Alien::Bit->dynamic_libs);
# Define opaque types for our bitset pointers
$ffi->type('opaque' => 'Bit_T');
$ffi->type('opaque*' => 'Bit_T_Ptr');
# Define our Bit_T functions
$ffi->attach(Bit_new => ['int'] => 'Bit_T' => sub {
my ($xsub, $self, $length) = @_;
die "Length must be a positive integer" unless defined $length && $length > 0;
my $bit_set = $xsub->($length);
die "Failed to create bit set" unless $bit_set;
return bless { _handle => $bit_set }, $self;
});
$ffi->attach(Bit_free => ['Bit_T_Ptr'] => 'opaque' => sub {
my ($xsub, $self) = @_;
my $ptr = \$self->{_handle};
return $xsub->($ptr);
});
$ffi->attach(Bit_length => ['Bit_T'] => 'int' => sub {
my ($xsub, $self) = @_;
return $xsub->($self->{_handle});
});
$ffi->attach(Bit_count => ['Bit_T'] => 'int' => sub {
my ($xsub, $self) = @_;
return $xsub->($self->{_handle});
});
$ffi->attach(Bit_buffer_size => ['int'] => 'int');
$ffi->attach(Bit_bset => ['Bit_T', 'int'] => 'void' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
$xsub->($self->{_handle}, $index);
});
$ffi->attach(Bit_bclear => ['Bit_T', 'int'] => 'void' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
$xsub->($self->{_handle}, $index);
});
$ffi->attach(Bit_get => ['Bit_T', 'int'] => 'int' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
return $xsub->($self->{_handle}, $index);
});
$ffi->attach(Bit_set => ['Bit_T', 'int', 'int'] => 'void' => sub {
my ($xsub, $self, $lo, $hi) = @_;
die "Low index must be non-negative" unless defined $lo && $lo >= 0;
die "High index must be greater than or equal to low index" unless defined $hi && $hi >= $lo;
$xsub->($self->{_handle}, $lo, $hi);
});
$ffi->attach(Bit_clear => ['Bit_T', 'int', 'int'] => 'void' => sub {
my ($xsub, $self, $lo, $hi) = @_;
die "Low index must be non-negative" unless defined $lo && $lo >= 0;
die "High index must be greater than or equal to low index" unless defined $hi && $hi >= $lo;
$xsub->($self->{_handle}, $lo, $hi);
});
# Comparison operations
$ffi->attach(Bit_eq => ['Bit_T', 'Bit_T'] => 'int' => sub {
my ($xsub, $self, $other) = @_;
die "Other bitset must be a Bit::Set object" unless ref $other eq ref $self;
return $xsub->($self->{_handle}, $other->{_handle});
});
# Set operations
$ffi->attach(Bit_union => ['Bit_T', 'Bit_T'] => 'Bit_T' => sub {
my ($xsub, $self, $other) = @_;
die "Other bitset must be a Bit::Set object" unless ref $other eq ref $self;
my $result_handle = $xsub->($self->{_handle}, $other->{_handle});
return bless { _handle => $result_handle }, ref $self;
});
$ffi->attach(Bit_inter => ['Bit_T', 'Bit_T'] => 'Bit_T' => sub {
my ($xsub, $self, $other) = @_;
die "Other bitset must be a Bit::Set object" unless ref $other eq ref $self;
my $result_handle = $xsub->($self->{_handle}, $other->{_handle});
return bless { _handle => $result_handle }, ref $self;
});
# Count operations
$ffi->attach(Bit_inter_count => ['Bit_T', 'Bit_T'] => 'int' => sub {
my ($xsub, $self, $other) = @_;
die "Other bitset must be a Bit::Set object" unless ref $other eq ref $self;
return $xsub->($self->{_handle}, $other->{_handle});
});
# Constructor and destructor
sub new {
my ($class, $length) = @_;
return $class->Bit_new($length);
}
sub DESTROY {
my ($self) = @_;
$self->Bit_free() if defined $self->{_handle};
}
# Convenient accessor methods
sub length {
my ($self) = @_;
return $self->Bit_length();
}
sub count {
my ($self) = @_;
return $self->Bit_count();
}
sub get {
my ($self, $index) = @_;
return $self->Bit_get($index);
}
sub set {
my ($self, $index) = @_;
$self->Bit_bset($index);
return $self;
}
sub clear {
my ($self, $index) = @_;
$self->Bit_bclear($index);
return $self;
}
sub set_range {
my ($self, $lo, $hi) = @_;
$self->Bit_set($lo, $hi);
return $self;
}
sub clear_range {
my ($self, $lo, $hi) = @_;
$self->Bit_clear($lo, $hi);
return $self;
}
sub equals {
my ($self, $other) = @_;
return $self->Bit_eq($other) ? 1 : 0;
}
sub union {
my ($self, $other) = @_;
return $self->Bit_union($other);
}
sub intersection {
my ($self, $other) = @_;
return $self->Bit_inter($other);
}
sub intersection_count {
my ($self, $other) = @_;
return $self->Bit_inter_count($other);
}
1;
Step 3: Create Bit::Set::DB module for packed containers
# /media/chrisarg/Software-Dev/Bit/perl-wrapper/lib/Bit/Set/DB.pm
package Bit::Set::DB;
use strict;
use warnings;
use FFI::Platypus;
use FFI::Platypus::Memory qw(malloc free);
use FFI::Platypus::Buffer qw(scalar_to_buffer buffer_to_scalar);
use Bit::Set;
use Alien::Bit;
# Create FFI::Platypus object
my $ffi = FFI::Platypus->new(api => 1);
# Add path to our dynamic library
$ffi->lib(Alien::Bit->dynamic_libs);
# Define opaque types for our bitset pointers
$ffi->type('opaque' => 'Bit_T');
$ffi->type('opaque' => 'Bit_T_DB');
$ffi->type('opaque*' => 'Bit_T_DB_Ptr');
# Define struct for SETOP_COUNT_OPTS
$ffi->type('record(SETOP_COUNT_OPTS)' => [
num_cpu_threads => 'int',
device_id => 'int',
upd_1st_operand => 'bool',
upd_2nd_operand => 'bool',
release_1st_operand => 'bool',
release_2nd_operand => 'bool',
release_counts => 'bool'
]);
# Define Bit_T_DB functions
$ffi->attach(BitDB_new => ['int', 'int'] => 'Bit_T_DB' => sub {
my ($xsub, $self, $length, $num_of_bitsets) = @_;
die "Length must be a positive integer" unless defined $length && $length > 0;
die "Number of bitsets must be a positive integer" unless defined $num_of_bitsets && $num_of_bitsets > 0;
my $db = $xsub->($length, $num_of_bitsets);
die "Failed to create bitset DB" unless $db;
return bless { _handle => $db }, $self;
});
$ffi->attach(BitDB_free => ['Bit_T_DB_Ptr'] => 'opaque' => sub {
my ($xsub, $self) = @_;
my $ptr = \$self->{_handle};
return $xsub->($ptr);
});
$ffi->attach(BitDB_length => ['Bit_T_DB'] => 'int' => sub {
my ($xsub, $self) = @_;
return $xsub->($self->{_handle});
});
$ffi->attach(BitDB_nelem => ['Bit_T_DB'] => 'int' => sub {
my ($xsub, $self) = @_;
return $xsub->($self->{_handle});
});
$ffi->attach(BitDB_count_at => ['Bit_T_DB', 'int'] => 'int' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
return $xsub->($self->{_handle}, $index);
});
$ffi->attach(BitDB_clear => ['Bit_T_DB'] => 'void' => sub {
my ($xsub, $self) = @_;
$xsub->($self->{_handle});
});
$ffi->attach(BitDB_clear_at => ['Bit_T_DB', 'int'] => 'void' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
$xsub->($self->{_handle}, $index);
});
$ffi->attach(BitDB_get_from => ['Bit_T_DB', 'int'] => 'Bit_T' => sub {
my ($xsub, $self, $index) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
my $bit_handle = $xsub->($self->{_handle}, $index);
return bless { _handle => $bit_handle }, 'Bit::Set';
});
$ffi->attach(BitDB_put_at => ['Bit_T_DB', 'int', 'Bit_T'] => 'void' => sub {
my ($xsub, $self, $index, $bitset) = @_;
die "Index must be non-negative" unless defined $index && $index >= 0;
die "Bitset must be a Bit::Set object" unless ref $bitset eq 'Bit::Set';
$xsub->($self->{_handle}, $index, $bitset->{_handle});
});
# CPU-specific intersection count function
$ffi->attach(BitDB_inter_count_cpu => ['Bit_T_DB', 'Bit_T_DB', 'SETOP_COUNT_OPTS'] => 'int*' => sub {
my ($xsub, $self, $other, $opts) = @_;
die "Other must be a Bit::Set::DB object" unless ref $other eq ref $self;
$opts ||= {
num_cpu_threads => 1,
device_id => -1,
upd_1st_operand => 0,
upd_2nd_operand => 0,
release_1st_operand => 0,
release_2nd_operand => 0,
release_counts => 0
};
return $xsub->($self->{_handle}, $other->{_handle}, $opts);
});
# Constructor and destructor
sub new {
my ($class, $length, $num_of_bitsets) = @_;
return $class->BitDB_new($length, $num_of_bitsets);
}
sub DESTROY {
my ($self) = @_;
$self->BitDB_free() if defined $self->{_handle};
}
# Convenient accessor methods
sub length {
my ($self) = @_;
return $self->BitDB_length();
}
sub num_of_bitsets {
my ($self) = @_;
return $self->BitDB_nelem();
}
sub count_at {
my ($self, $index) = @_;
return $self->BitDB_count_at($index);
}
sub clear {
my ($self) = @_;
$self->BitDB_clear();
return $self;
}
sub clear_at {
my ($self, $index) = @_;
$self->BitDB_clear_at($index);
return $self;
}
sub get_bitset {
my ($self, $index) = @_;
return $self->BitDB_get_from($index);
}
sub put_bitset {
my ($self, $index, $bitset) = @_;
$self->BitDB_put_at($index, $bitset);
return $self;
}
sub intersection_count_cpu {
my ($self, $other, $opts) = @_;
return $self->BitDB_inter_count_cpu($other, $opts);
}
1;
Step 4: Example usage script
#!/usr/bin/perl
use strict;
use warnings;
use Bit::Set;
use Bit::Set::DB;
# Create a new bitset with 1024 bits
my $bitset1 = Bit::Set->new(1024);
my $bitset2 = Bit::Set->new(1024);
# Set some bits
$bitset1->set(42);
$bitset1->set(100);
$bitset2->set(42);
$bitset2->set(200);
# Check if a bit is set
print "Bit 42 in bitset1: ", $bitset1->get(42), "\n";
print "Bit 100 in bitset1: ", $bitset1->get(100), "\n";
print "Bit 200 in bitset1: ", $bitset1->get(200), "\n";
# Count the number of bits set
print "Number of bits set in bitset1: ", $bitset1->count(), "\n";
print "Number of bits set in bitset2: ", $bitset2->count(), "\n";
# Calculate intersection count
my $intersection_count = $bitset1->intersection_count($bitset2);
print "Intersection count: $intersection_count\n";
# Create a new bitset as the union of the two bitsets
my $union = $bitset1->union($bitset2);
print "Number of bits set in union: ", $union->count(), "\n";
# Create a BitDB with 3 bitsets of length 1024
my $db = Bit::Set::DB->new(1024, 3);
# Put our bitsets into the DB
$db->put_bitset(0, $bitset1);
$db->put_bitset(1, $bitset2);
$db->put_bitset(2, $union);
# Count bits in each bitset in the DB
print "Bits set in DB at index 0: ", $db->count_at(0), "\n";
print "Bits set in DB at index 1: ", $db->count_at(1), "\n";
print "Bits set in DB at index 2: ", $db->count_at(2), "\n";
Modifications for Intermediate Level (Inline::C)
For intermediate-level Perl programmers, here are the changes required to implement the wrapper using Inline::C:
# Bit::Set using Inline::C
package Bit::Set;
use strict;
use warnings;
use Inline C => Config =>
BUILD_NOISY => 1,
CLEAN_AFTER_BUILD => 0,
LIBS => '-L/media/chrisarg/Software-Dev/Bit/bit/build -lbit',
INC => '-I/media/chrisarg/Software-Dev/Bit/bit/include';
use Inline C => <<'END_C';
#include "bit.h"
typedef struct Bit_T* Bit_T;
// Wrapper functions
Bit_T create_bitset(int length) {
return Bit_new(length);
}
void free_bitset(Bit_T set) {
Bit_free(&set);
}
int get_length(Bit_T set) {
return Bit_length(set);
}
int get_count(Bit_T set) {
return Bit_count(set);
}
void set_bit(Bit_T set, int index) {
Bit_bset(set, index);
}
void clear_bit(Bit_T set, int index) {
Bit_bclear(set, index);
}
int get_bit(Bit_T set, int index) {
return Bit_get(set, index);
}
// Add more wrapper functions as needed
END_C
# Perl OO interface
sub new {
my ($class, $length) = @_;
my $handle = create_bitset($length);
return bless { _handle => $handle }, $class;
}
# Add more methods similar to the FFI version
Modifications for Advanced Level (XS)
For advanced Perl programmers, here are the key changes required to implement using XS:
# Bit::Set.xs
#include "EXTERN.h"
#include "perl.h"
#include "XSUB.h"
#include "bit.h"
typedef struct Bit_T* Bit_T;
typedef struct Bit_T_DB* Bit_T_DB;
MODULE = Bit::Set PACKAGE = Bit::Set
PROTOTYPES: DISABLE
Bit_T
Bit_new(length)
int length
void
Bit_free(set)
Bit_T set
CODE:
Bit_free(&set);
int
Bit_length(set)
Bit_T set
int
Bit_count(set)
Bit_T set
void
Bit_bset(set, index)
Bit_T set
int index
# Add more functions as needed
And update the Makefile.PL:
use ExtUtils::MakeMaker;
WriteMakefile(
NAME => 'Bit::Set',
VERSION_FROM => 'lib/Bit/Set.pm',
LIBS => ['-L/media/chrisarg/Software-Dev/Bit/bit/build -lbit'],
INC => '-I/media/chrisarg/Software-Dev/Bit/bit/include',
OBJECT => '$(O_FILES)',
);
Conclusion
For most users, especially beginners, the FFI::Platypus approach offers the best balance of simplicity, performance, and maintainability. It works well with your existing dynamic library build process and provides a clean, object-oriented interface to the Bit_T and Bit_T_DB types. The implementation provided covers all the core functionality while being extensible for additional features as needed.
My critique of Claude’s choices
In this first post, we will not consider the implementation(s) which will be covered in separate posts, but will restrict ourselves to Claude’s output with respect to the other questions. I give Claude bonus points for clearly identifying the niches for each potential choice:
- Highighting that SWIG can support wrapping for other languages)
- Proposing Foreign Function Interface for linking to the dynamic library for beginners.
- A experienced programmer would opt for XS is not a surprise at all.
However:
- the choice of Inline for the intermediate user is head-scratching: it seems that the chatbot closed on the intermediate level of programming experience in the prompt, and the selection of the approach was driven entirely by the fact that the user could (presumably) do more stuff in C.
- SWIG was not considered as suitable (perhaps because few people in the training databases use SWIG) for implementing at any level. Without going into the specifics of the implementation though, I’d feel comfortable opting for FFI as an initial step for largely the reasons identified by Claude. We will have more things to say about the FFI implementation in the subsequent post in this series.
I alerted the bot to the (substantial) risk of hallucinations and decreased
-
Note, I did not use the word understanding, as I do not think that LLMs can understant: they are merely noisy statistical pattern generators that can be tasked to create rough solutions for refining. ↩
<h3 class='likesectionHead' id='missing-integers-dont-make-me-mad-just-disappointed'><a id='x1-1000'></a>Missing Integers Don’t Make Me MAD, Just Disappointed</h3>
RabbitFarm PerlPublished on Sunday 29 June 2025 12:09
The examples used here are from the weekly challenge problem statement and demonstrate the working solution.
Part 1: Missing Integers
You are given an array of n integers. Write a script to find all the missing integers in the range 1..n in the given array.
The core of the solution is contained in a single subroutine. The resulting code can be contained in a single file.
The approach we take is to use the given array as hash keys. Then we’ll iterate over the range 1..n and see which hash keys are missing.
-
sub find_missing{
my %h = ();
my @missing = ();
do{ $h{$_} = -1 } for @_;
@missing = grep {!exists($h{$_})} 1 .. @_;
return @missing;
}
◇
-
Fragment referenced in 1.
Just to make sure things work as expected we’ll define a few short tests.
-
MAIN:{
say q/(/ . join(q/, /, find_missing 1, 2, 1, 3, 2, 5) . q/)/;
say q/(/ . join(q/, /, find_missing 1, 1, 1) . q/)/;
say q/(/ . join(q/, /, find_missing 2, 2, 1) . q/)/;
}
◇
-
Fragment referenced in 1.
Sample Run
$ perl perl/ch-1.pl (4, 6) (2, 3) (3)
Part 2: MAD
You are given an array of distinct integers. Write a script to find all pairs of elements with minimum absolute difference (MAD) of any two elements.
We’ll use a hash based approach like we did in Part 1. The amount of code is small, just a single subroutine.
Since we need to have a nested loop to access all pairs we’ll make an effort to only do it once. What we’ll do is store the pairs in a list keyed by the differences. We’ll also track the minimum difference in a variable to avoid sorting to find it later.
-
sub mad_pairs{
my %mad = ();
my $mad = ~0;
for my $i (0 .. @_ - 1){
for my $j ($i + 1 .. @_ - 1){
my $d = abs($_[$i] - $_[$j]);
$mad = $d if $d < $mad;
push @{$mad{$d}}, [$_[$i], $_[$j]];
}
}
return @{$mad{$mad}};
}
◇
-
Fragment referenced in 4.
The main section is just some basic tests. Yeah, we’ll do lazy string formatting with chop!
-
MAIN:{
my $s = q//;
do{
$s .= q/[/ . join(q/, /, @{$_}) . q/], /;
} for mad_pairs 4, 1, 2, 3;
chop $s;
chop $s;
say $s;
$s = q//;
do{
$s .= q/[/ . join(q/, /, @{$_}) . q/], /;
} for mad_pairs 1, 3, 7, 11, 15;
chop $s;
chop $s;
say $s;
$s = q//;
do{
$s .= q/[/ . join(q/, /, @{$_}) . q/], /;
} for mad_pairs 1, 5, 3, 8;
chop $s;
chop $s;
say $s;
$s = q//;
}
◇
-
Fragment referenced in 4.
Sample Run
$ perl perl/ch-2.pl [4, 3], [1, 2], [2, 3] [1, 3] [1, 3], [5, 3]
References
(dliv) 4 great CPAN modules released last week
NiceperlPublished by prz on Saturday 28 June 2025 17:14
-
App::Netdisco - An open source web-based network management tool.
- Version: 2.086003 on 2025-06-21, with 17 votes
- Previous CPAN version: 2.086002 was 3 days before
- Author: OLIVER
-
LWP - The World-Wide Web library for Perl
- Version: 6.79 on 2025-06-27, with 171 votes
- Previous CPAN version: 6.78 was 4 months, 7 days before
- Author: OALDERS
-
Promises - An implementation of Promises in Perl
- Version: 1.05 on 2025-06-25, with 42 votes
- Previous CPAN version: 1.04 was 5 years, 4 months, 2 days before
- Author: YANICK
-
SPVM - The SPVM Language
- Version: 0.990075 on 2025-06-26, with 36 votes
- Previous CPAN version: 0.990071 was 8 days before
- Author: KIMOTO
Recently, Gabor ran a poll in a Perl Facebook community asking which version of Perl people used in their production systems. The results were eye-opening—and not in a good way. A surprisingly large number of developers replied with something along the lines of “whatever version is included with my OS.”
If that’s you, this post is for you. I don’t say that to shame or scold—many of us started out this way. But if you’re serious about writing and running Perl in 2025, it’s time to stop relying on the system Perl.
Let’s unpack why.
What is “System Perl”?
When we talk about the system Perl, we mean the version of Perl that comes pre-installed with your operating system—be it a Linux distro like Debian or CentOS, or even macOS. This is the version used by the OS itself for various internal tasks and scripts. It’s typically located in /usr/bin/perl and tied closely to system packages.
It’s tempting to just use what’s already there. But that decision brings a lot of hidden baggage—and some very real risks.
Which versions of Perl are officially supported?
The Perl Core Support Policy states that only the two most recent stable release series of Perl are supported by the Perl development team [Update: fixed text in previous sentence]. As of mid-2025, that means:
-
Perl 5.40 (released May 2024)
-
Perl 5.38 (released July 2023)
If you’re using anything older—like 5.36, 5.32, or 5.16—you’re outside the officially supported window. That means no guaranteed bug fixes, security patches, or compatibility updates from core CPAN tools like ExtUtils::MakeMaker, Module::Build, or Test::More.
Using an old system Perl often means you’re several versions behind, and no one upstream is responsible for keeping that working anymore.
Why using System Perl is a problem
1. It’s often outdated
System Perl is frozen in time—usually the version that was current when the OS release cycle began. Depending on your distro, that could mean Perl 5.10, 5.16, or 5.26—versions that are years behind the latest stable Perl (currently 5.40).
This means you’re missing out on:
-
New language features (
builtin,class/method/field,signatures,try/catch) -
Performance improvements
-
Bug fixes
-
Critical security patches
- Support: anything older than Perl 5.38 is no longer officially maintained by the core Perl team
If you’ve ever looked at modern Perl documentation and found your code mysteriously breaking, chances are your system Perl is too old.
2. It’s not yours to mess with
System Perl isn’t just a convenience—it’s a dependency. Your operating system relies on it for package management, system maintenance tasks, and assorted glue scripts. If you install or upgrade CPAN modules into the system Perl (especially with cpan or cpanm as root), you run the risk of breaking something your OS depends on.
It’s a kind of dependency hell that’s completely avoidable—if you stop using system Perl.
3. It’s a barrier to portability and reproducibility
When you use system Perl, your environment is essentially defined by your distro. That’s fine until you want to:
-
Move your application to another system
-
Run CI tests on a different platform
-
Upgrade your OS
-
Onboard a new developer
You lose the ability to create predictable, portable environments. That’s not a luxury—it’s a requirement for sane development in modern software teams.
What you should be doing instead
1. Use perlbrew or plenv
These tools let you install multiple versions of Perl in your home directory and switch between them easily. Want to test your code on Perl 5.32 and 5.40? perlbrew makes it a breeze.
You get:
-
A clean separation from system Perl
-
The freedom to upgrade or downgrade at will
-
Zero risk of breaking your OS
It takes minutes to set up and pays for itself tenfold in flexibility.
2. Use local::lib or Carton
Managing CPAN dependencies globally is a recipe for pain. Instead, use:
-
local::lib: keeps modules in your home directory. -
Carton: locks your CPAN dependencies (likenpmorpip) so deployments are repeatable.
Your production system should run with exactly the same modules and versions as your dev environment. Carton helps you achieve that.
3. Consider Docker
If you’re building larger apps or APIs, containerising your Perl environment ensures true consistency across dev, test, and production. You can even start from a system Perl inside the container—as long as it’s isolated and under your control.
You never want to be the person debugging a bug that only happens on production, because prod is using the distro’s ancient Perl and no one can remember which CPAN modules got installed by hand.
The benefits of managing your own Perl
Once you step away from the system Perl, you gain:
-
Access to the full language. Use the latest features without backports or compatibility hacks.
-
Freedom from fear. Install CPAN modules freely without the risk of breaking your OS.
-
Portability. Move projects between machines or teams with minimal friction.
-
Better testing. Easily test your code across multiple Perl versions.
-
Security. Stay up to date with patches and fixes on your schedule, not the distro’s.
-
Modern practices. Align your Perl workflow with the kinds of practices standard in other languages (think
virtualenv,rbenv,nvm, etc.).
“But it just works…”
I know the argument. You’ve got a handful of scripts, or maybe a cron job or two, and they seem fine. Why bother with all this?
Because “it just works” only holds true until:
-
You upgrade your OS and Perl changes under you.
-
A script stops working and you don’t know why.
-
You want to install a module and suddenly
aptis yelling at you about conflicts. -
You realise the module you need requires Perl 5.34, but your system has 5.16.
Don’t wait for it to break. Get ahead of it.
The first step
You don’t have to refactor your entire setup overnight. But you can do this:
-
Install
perlbrewand try it out. -
Start a new project with
Cartonto lock dependencies. -
Choose a current version of Perl and commit to using it moving forward.
Once you’ve seen how smooth things can be with a clean, controlled Perl environment, you won’t want to go back.
TL;DR
Your system Perl is for your operating system—not for your apps. Treat it as off-limits. Modern Perl deserves modern tools, and so do you.
Take the first step. Your future self (and probably your ops team) will thank you.
The post Stop using your system Perl first appeared on Perl Hacks.
Full Stack Developer with strong Perl expertise, maryland (Resourcesys)
Perl JobsPublished on Thursday 26 June 2025 00:00
Start Date: Immediate
Position Type: Contract
Location: Remote
Seeking a Full Stack Developer with strong Perl expertise and experience in PostgreSQL and AWS, particularly in multi-tenant architectures.
Must have full-stack experience including front-end (HTML/CSS/JS), and thrive in a structured Waterfall development environment with thorough documentation and testing.
Preferred candidates have experience with scalable registration portals, authentication methods (OAuth/SAML), and basic DevOps (CI/CD, IaC).
Job Overview
We are seeking a highly skilled Full Stack Developer with expertise in Perl to join our team. The ideal candidate will be responsible for developing and maintaining a registration-based portal with a multi-tenant database structure. This application is hosted on AWS, using PostgreSQL as the primary database.
This role involves full-stack development, including both back-end logic and front-end implementation. The position requires working within a Waterfall development environment, ensuring clear documentation, structured processes, and rigorous testing.
Key Responsibilities
Develop & Maintain: Design, develop, and maintain robust full-stack applications using Perl for backend logic.
Database Management: Work with PostgreSQL, designing and optimizing database queries, ensuring efficiency in a multi-tenant architecture.
AWS Hosting: Manage and optimize application hosting on AWS (EC2, S3, RDS, etc.).
Front-End Development: Implement front-end interfaces and workflows, ensuring usability and performance.
Code Review & Testing: Conduct thorough code reviews and ensure high-quality releases following Waterfall methodology.
Collaboration: Work closely with business analysts, project managers, and QA teams to define requirements and deliver solutions.
Security & Compliance: Implement security best practices, ensuring compliance with relevant industry standards.
Required Skills & Qualifications
5+ years of professional experience as a Full Stack Developer.
Expertise in Perl development, including experience with Modern Perl frameworks (Mojolicious, Dancer, Catalyst, etc.).
Strong experience with PostgreSQL, including writing and optimizing queries.
Experience working in AWS environments (EC2, S3, RDS, IAM).
Front-end development skills with proficiency in HTML, CSS, JavaScript, and frameworks like Bootstrap or React.
Experience working in a Waterfall development environment.
Strong debugging and troubleshooting skills.
Ability to document processes, technical designs, and application workflows.
Preferred Qualifications
Experience with multi-tenant database structures and designing scalable applications.
Understanding of authentication & authorization mechanisms (OAuth, SAML, etc.).
Exposure to DevOps practices (CI/CD, Infrastructure as Code).
Previous experience working with registration-based portals.
Analysing FIT data with Perl: producing PNG plots
perl.comPublished on Wednesday 25 June 2025 10:10
Last time, we worked out how to extract, collate, and print statistics about the data contained in a FIT file. Now we’re going to take the next logical step and plot the time series data.
Start plotting with Gnu
Now that we’ve extracted data from the FIT file, what else can we do with
it? Since this is time series data, the most natural next step is to
visualise the data values over time. Since I know that
Gnuplot handles time series data
well,1 I chose to use
Chart::Gnuplot to plot the
data.
An additional point in Gnuplot’s favour is that it can plot two datasets on the same graph, each with its own y-axis. Such functionality is handy when searching for correlations between datasets of different y-axis scales and ranges that share the same baseline data series.
Clearly Chart::Gnuplot relies on Gnuplot, so we need to install it first:
$ sudo apt install -y gnuplot
Now we can install Chart::Gnuplot with cpanm:
$ cpanm Chart::Gnuplot
Putting our finger on the pulse
Something I like looking at is how my heart rate evolved throughout a ride; it gives me an idea of how much effort I was putting in. So, we’ll start off by looking at how the heart rate data varied over time. In other words, we want time on the x-axis and heart rate on the y-axis.
One great thing about Gnuplot is that if you give it a format string for the time data, then plotting “just works”. In other words, explicit conversion to datetime data for the x-axis is unnecessary.
Here’s a script to extract the FIT data from our example data file. It
displays some statistics about the activity and plots heart rate versus
time. I’ve given the script the filename geo-fit-plot-data.pl:
1use strict;
2use warnings;
3
4use Geo::FIT;
5use Scalar::Util qw(reftype);
6use List::Util qw(max sum);
7use Chart::Gnuplot;
8
9
10sub main {
11 my @activity_data = extract_activity_data();
12
13 show_activity_statistics(@activity_data);
14 plot_activity_data(@activity_data);
15}
16
17sub extract_activity_data {
18 my $fit = Geo::FIT->new();
19 $fit->file( "2025-05-08-07-58-33.fit" );
20 $fit->open or die $fit->error;
21
22 my $record_callback = sub {
23 my ($self, $descriptor, $values) = @_;
24 my @all_field_names = $self->fields_list($descriptor);
25
26 my %event_data;
27 for my $field_name (@all_field_names) {
28 my $field_value = $self->field_value($field_name, $descriptor, $values);
29 if ($field_value =~ /[a-zA-Z]/) {
30 $event_data{$field_name} = $field_value;
31 }
32 }
33
34 return \%event_data;
35 };
36
37 $fit->data_message_callback_by_name('record', $record_callback ) or die $fit->error;
38
39 my @header_things = $fit->fetch_header;
40
41 my $event_data;
42 my @activity_data;
43 do {
44 $event_data = $fit->fetch;
45 my $reftype = reftype $event_data;
46 if (defined $reftype && $reftype eq 'HASH' && defined %$event_data{'timestamp'}) {
47 push @activity_data, $event_data;
48 }
49 } while ( $event_data );
50
51 $fit->close;
52
53 return @activity_data;
54}
55
56# extract and return the numerical parts of an array of FIT data values
57sub num_parts {
58 my $field_name = shift;
59 my @activity_data = @_;
60
61 return map { (split ' ', $_->{$field_name})[0] } @activity_data;
62}
63
64# return the average of an array of numbers
65sub avg {
66 my @array = @_;
67
68 return (sum @array) / (scalar @array);
69}
70
71sub show_activity_statistics {
72 my @activity_data = @_;
73
74 print "Found ", scalar @activity_data, " entries in FIT file\n";
75 my $available_fields = join ", ", sort keys %{$activity_data[0]};
76 print "Available fields: $available_fields\n";
77
78 my $total_distance_m = (split ' ', ${$activity_data[-1]}{'distance'})[0];
79 my $total_distance = $total_distance_m/1000;
80 print "Total distance: $total_distance km\n";
81
82 my @speeds = num_parts('speed', @activity_data);
83 my $maximum_speed = max @speeds;
84 my $maximum_speed_km = $maximum_speed*3.6;
85 print "Maximum speed: $maximum_speed m/s = $maximum_speed_km km/h\n";
86
87 my $average_speed = avg(@speeds);
88 my $average_speed_km = sprintf("%0.2f", $average_speed*3.6);
89 $average_speed = sprintf("%0.2f", $average_speed);
90 print "Average speed: $average_speed m/s = $average_speed_km km/h\n";
91
92 my @powers = num_parts('power', @activity_data);
93 my $maximum_power = max @powers;
94 print "Maximum power: $maximum_power W\n";
95
96 my $average_power = avg(@powers);
97 $average_power = sprintf("%0.2f", $average_power);
98 print "Average power: $average_power W\n";
99
100 my @heart_rates = num_parts('heart_rate', @activity_data);
101 my $maximum_heart_rate = max @heart_rates;
102 print "Maximum heart rate: $maximum_heart_rate bpm\n";
103
104 my $average_heart_rate = avg(@heart_rates);
105 $average_heart_rate = sprintf("%0.2f", $average_heart_rate);
106 print "Average heart rate: $average_heart_rate bpm\n";
107}
108
109sub plot_activity_data {
110 my @activity_data = @_;
111
112 my @heart_rates = num_parts('heart_rate', @activity_data);
113 my @times = map { $_->{'timestamp'} } @activity_data;
114
115 my $date = "2025-05-08";
116
117 my $chart = Chart::Gnuplot->new(
118 output => "watopia-figure-8-heart-rate.png",
119 title => "Figure 8 in Watopia on $date: heart rate over time",
120 xlabel => "Time",
121 ylabel => "Heart rate (bpm)",
122 terminal => "png size 1024, 768",
123 timeaxis => "x",
124 xtics => {
125 labelfmt => '%H:%M',
126 },
127 );
128
129 my $data_set = Chart::Gnuplot::DataSet->new(
130 xdata => \@times,
131 ydata => \@heart_rates,
132 timefmt => "%Y-%m-%dT%H:%M:%SZ",
133 style => "lines",
134 );
135
136 $chart->plot2d($data_set);
137}
138
139main();
A lot has happened between this code and the previous scripts. Let’s review it to see what’s changed.
The biggest changes were structural. I’ve moved the code into separate routines, improving encapsulation and making each more focused on one task.
The FIT file data extraction code I’ve put into its own routine
(extract_activity_data(); lines 17-54). This sub returns the array of
event data that we’ve been
using.
I’ve also created two utility routines num_parts() (lines 57-62) and
avg() (lines 65-69). These return the numerical parts of the activity
data and average data series value, respectively.
The ride statistics calculation and display code is now located in the
show_activity_statistics() routine. Now it’s out of the way, allowing us
to concentrate on other things.
The plotting code is new and sits in a sub called plot_activity_data()
(lines 109-137). We’ll focus much more on that later.
These routines are called from a main() routine (lines 10-15) giving us a
nice bird’s eye view of what the script is trying to achieve. Running all
the code is now as simple as calling main() (line 139).
Particulars of pulse plotting
Let’s zoom in on the plotting code in plot_activity_data(). After having
imported Chart::Gnuplot at the top of the file (line 7), we need to do a
bit of organising before we can set up the chart. We extract the activity
data with extract_activity_data() (line 11) and pass this as an argument
to plot_activity_data() (line 14). At the top of plot_activity_data()
we fetch an array of the numerical heart rate data (line 112) and an array
of all the timestamps (line 113).
The activity’s date (line 115) is assigned as a string variable because I want this to appear in the chart’s title. Although the date is present in the activity data, I’ve chosen not to calculate its value until later. This way we get the plotting code up and running sooner, as there’s still a lot to discuss.
Now we’re ready to set up the chart, which takes place on lines 117-127.
We create a new Chart::Gnuplot object on line 117 and configure the plot
with various keyword arguments to the object’s constructor.
The parameters are as follows:
outputspecifies the name of the output file as a string. The name I’ve chosen reflects the activity as well as the data being plotted.titleis a string to use as the plot’s title. To provide context, I mention the name of the route (Figure 8) within Zwift’s main virtual world (Watopia) as well as the date of the activity. To highlight that we’re plotting heart rate over time, I’ve mentioned this in the title also.xlabelis a string describing the x-axis data.ylabelis a string describing the y-axis data.- the
terminaloption tells Gnuplot to use the PNG2 “terminal”3 and to set its dimensions to 1024x768. timeaxistells Gnuplot which axis contains time-based data (in this case the x-axis). This enables Gnuplot to space out the data along the axis evenly. Often, the spacing between points in time-based data isn’t regular; for instance, data points can be missing. Hence, naively plotting unevenly-spaced time data can produce a distorted graph. Telling Gnuplot that the x-axis contains time-based data allows it to add appropriate space where necessary.xticsis a hash of options to configure the behaviour of the ticks on the x-axis. The setting here displays hour and minute information at each tick mark for our time data. We omit the year, month and day information as this is the same for all data points.
Now that the main chart parameters have been set, we can focus on the data
we want to plot. In Chart::Gnuplot parlance, a Chart::Gnuplot::DataSet
object represents a set of data to plot. Lines 129-134 instantiate such an
object which we later pass to the Chart::Gnuplot object when plotting the
data (line 136). One configures Chart::Gnuplot::DataSet objects similarly
to how Chart::Gnuplot objects are constructed: by passing various options
to its constructor. These options include the data to plot and how this
data should be styled on the graph.
The options used here have the following meanings:
xdatais an array reference to the data to use for the x-axis. If this option is omitted, then Gnuplot uses the array indices of the y-data as the x-axis values.ydatais an array reference to the data to use for the y-axis.timefmtspecifies the format string Gnuplot should use when reading the time data in thexdataarray. Timestamps are strings and we need to inform Gnuplot how to parse them into a form useful for x-axis data. Were the x-axis data a numerical data type, this option wouldn’t be necessary.styleis a string specifying the style to use for plotting the data. In this example, we’re plotting the data points as a set of connected lines. Check out theChart::Gnuplotdocumentation for a full list of the available style options.
We finally get to plot the data on line 136. The data set gets passed to
the Chart::Gnuplot object as the argument to its plot2d() method. As
its name suggests, this plots 2D data, i.e. y versus x. Gnuplot can also
display 3D data, in which case we’d call plot3d(). When plotting 3D data
we’d have to include a z dimension when setting up the data set.
Running this code
$ perl geo-fit-plot-data.pl
generates this plot:
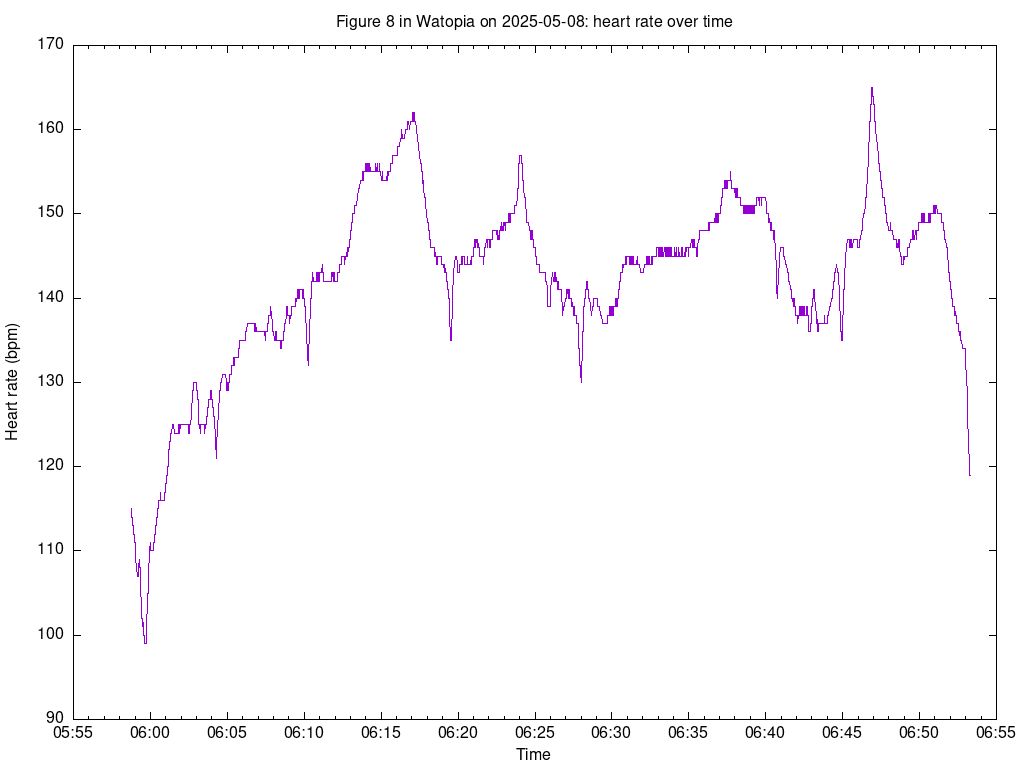
A couple of things are apparent when looking at this graph. It took me a while to get going (my pulse rose steadily over the first ~15 minutes of the ride) and the time is weird (6 am? Me? Lol, no). We’ll try to explain the heart rate behaviour later.
But first, what’s up with the time data? Did I really start riding at 6 o’clock in the morning? I’m not a morning person, so that’s not right. Also, I’m pretty sure my neighbours wouldn’t appreciate me coughing and wheezing at 6 am while trying to punish myself on Zwift. So what’s going on?
For those following carefully, you might have noticed the trailing Z on
the timestamp data. This means that the time zone is UTC. Given that this
data is from May and I live in Germany, this implies that the local time
would have been 8 am. Still rather early for me, but not too early to
disturb the neighbours too much.4 In other
words, we need to fix the time zone to get the time data right.
Getting into the zone
How do we fix the time zone? I’m glad you asked! We need to parse the
timestamp into a DateTime object, set the time zone, and then pass the
fixed time data to Gnuplot. It turns out that the standard DateTime
library doesn’t parse date/time strings.
Instead, we need to use
DateTime::Format::Strptime.
This module parses date/time strings much like the strptime(3) POSIX
function
does and returns DateTime objects.
Since the module isn’t part of the core Perl distribution, we need to install it:
$ cpanm DateTime::Format::Strptime
Most of the code changes that follow take place only within the plotting
routine (plot_activity_data()). So, I’m going to focus on that from now
on and won’t create a new script for the new version of the code.
The first thing to do is to import the DateTime::Format::Strptime module:
use Scalar::Util qw(reftype);
use List::Util qw(max sum);
use Chart::Gnuplot;
+use DateTime::Format::Strptime;
Extending plot_activity_data() to set the correct time zone, we get this
code:
1sub plot_activity_data {
2 my @activity_data = @_;
3
4 # extract data to plot from full activity data
5 my @heart_rates = num_parts('heart_rate', @activity_data);
6 my @timestamps = map { $_->{'timestamp'} } @activity_data;
7
8 # fix time zone in time data
9 my $date_parser = DateTime::Format::Strptime->new(
10 pattern => "%Y-%m-%dT%H:%M:%SZ",
11 time_zone => 'UTC',
12 );
13
14 my @times = map {
15 my $dt = $date_parser->parse_datetime($_);
16 $dt->set_time_zone('Europe/Berlin');
17 my $time_string = $dt->strftime("%H:%M:%S");
18 $time_string;
19 } @timestamps;
20
21 # determine date from timestamp data
22 my $dt = $date_parser->parse_datetime($timestamps[0]);
23 my $date = $dt->strftime("%Y-%m-%d");
24
25 # plot data
26 my $chart = Chart::Gnuplot->new(
27 output => "watopia-figure-8-heart-rate.png",
28 title => "Figure 8 in Watopia on $date: heart rate over time",
29 xlabel => "Time",
30 ylabel => "Heart rate (bpm)",
31 terminal => "png size 1024, 768",
32 timeaxis => "x",
33 xtics => {
34 labelfmt => '%H:%M',
35 },
36 );
37
38 my $data_set = Chart::Gnuplot::DataSet->new(
39 xdata => \@times,
40 ydata => \@heart_rates,
41 timefmt => "%H:%M:%S",
42 style => "lines",
43 );
44
45 $chart->plot2d($data_set);
46}
The timestamp data is no longer read straight into the @times array; it’s
stored in the @timestamps temporary array (line 6). This change also
makes the variable naming a bit more consistent, which is nice.
To parse a timestamp string into a DateTime object, we need to tell
DateTime::Format::Strptime how to format the timestamp (lines 8-12). This
is the purpose of the pattern argument in the DateTime::Format::Strptime
constructor (line 10). You might have noticed that we used the same pattern
when telling Gnuplot what format the time data was in. We also specify the
time zone (line 11) to ensure that the date/time data is parsed as UTC.
Next, we fix the time zone in all elements of the @timestamps array (lines
14-19). I’ve chosen to do this within a map here. I could extract this
code into a well-named routine, but it does the job for now. The map
parses the date/time string into a Date::Time object (line 15) and sets
the time zone to Europe/Berlin5 (line 16). We only need to
plot the time data,6 hence we format the DateTime
object as a string including only hour, minute and second information (line
17). Even though we only use hours and minutes for the x-axis tick labels
later, the time data is resolved down to the second, hence we retain the
seconds information in the @times array.
One could write a more compact version of the time zone correction code like this:
my @times = map {
$date_parser->parse_datetime($_)
->set_time_zone('Europe/Berlin')
->strftime("%H:%M:%S");
} @timestamps;
yet, in this case, I find giving each step a name (via a variable) helps the code explain itself. YMMV.
The next chunk of code (lines 22-23) isn’t related to the time zone fix. It
generalises working out the current date from the activity data. This way I
can use a FIT file from a different activity without having to update the
$date variable by hand. The process is simple: all elements of the
@timestamps array have the same date, so we choose to parse only the first
one (line 22)7. This gives us a DateTime object
which we convert into a formatted date string (via the strftime() method)
composed of the year, month and day (line 23). We don’t need to fix the
time zone because UTC is sufficient in this case to extract the date
information. Of course, if you’re in a time zone close to the international
date line you might need to set the time zone to get the correct date.
The last thing to change is the timefmt option to the
Chart::Gnuplot::DataSet object on line 41. Because we now only have hour,
minute and second information, we need to update the time format string to
reflect this.
Now we’re ready to run the script again! Doing so
$ perl geo-fit-plot-data.pl
creates this graph
where we see that the time information is correct. Yay! 🎉
How long can this go on?
Now that I look at the graph again, I realise something: it doesn’t matter
when the data was taken (at least, not for this use case). What matters
more is the elapsed time from the start of the activity until the end. It
looks like we need to munge the time
data again. The job now is to convert the timestamp information into
seconds elapsed since the ride began. Since we’ve parsed the timestamp data
into DateTime objects (in line 15 above), we can convert that value into
the number of seconds since the epoch (via the epoch()
method). As soon as we
know the epoch value for each element in the @timestamps array, we can
subtract the first element’s epoch value from each element in the array.
This will give us an array containing elapsed seconds since the beginning of
the activity. Elapsed seconds are a bit too fine-grained for an activity
extending over an hour, so we’ll also convert seconds to minutes.
Making these changes to the plot_activity_data() code, we get:
1sub plot_activity_data {
2 my @activity_data = @_;
3
4 # extract data to plot from full activity data
5 my @heart_rates = num_parts('heart_rate', @activity_data);
6 my @timestamps = map { $_->{'timestamp'} } @activity_data;
7
8 # parse timestamp data
9 my $date_parser = DateTime::Format::Strptime->new(
10 pattern => "%Y-%m-%dT%H:%M:%SZ",
11 time_zone => 'UTC',
12 );
13
14 # get the epoch time for the first point in the time data
15 my $first_epoch_time = $date_parser->parse_datetime($timestamps[0])->epoch;
16
17 # convert timestamp data to elapsed minutes from start of activity
18 my @times = map {
19 my $dt = $date_parser->parse_datetime($_);
20 my $epoch_time = $dt->epoch;
21 my $elapsed_time = ($epoch_time - $first_epoch_time)/60;
22 $elapsed_time;
23 } @timestamps;
24
25 # determine date from timestamp data
26 my $dt = $date_parser->parse_datetime($timestamps[0]);
27 my $date = $dt->strftime("%Y-%m-%d");
28
29 # plot data
30 my $chart = Chart::Gnuplot->new(
31 output => "watopia-figure-8-heart-rate.png",
32 title => "Figure 8 in Watopia on $date: heart rate over time",
33 xlabel => "Elapsed time (min)",
34 ylabel => "Heart rate (bpm)",
35 terminal => "png size 1024, 768",
36 );
37
38 my $data_set = Chart::Gnuplot::DataSet->new(
39 xdata => \@times,
40 ydata => \@heart_rates,
41 style => "lines",
42 );
43
44 $chart->plot2d($data_set);
45}
The main changes occur in lines 14-23. We parse the date/time information
from the first timestamp (line 15), chaining the epoch() method call to
find the number of seconds since the epoch. We store this result in a
variable for later use; it holds the epoch time at the beginning of the data
series. After parsing the timestamps into DateTime objects (line 19), we
find the epoch time for each time point (line 20). Line 21 calculates the
elapsed time from the time stored in $first_epoch_time and converts
seconds to minutes by dividing by 60. The map returns this value (line
22) and hence @times now contains a series of elapsed time values in
minutes.
It’s important to note here that we’re no longer plotting a date/time value
on the x-axis; the elapsed time is a purely numerical value. Thus, we
update the x-axis label string (line 33) to highlight this fact and remove
the timeaxis and xtics/labelfmt options from the Chart::Gnuplot
constructor. The timefmt option to the Chart::Gnuplot::DataSet
constructor is also no longer necessary and it too has been removed.
The script is now ready to go!
Running it
$ perl geo-fit-plot-data.pl
gives
That’s better!
Reaching for the sky
Our statistics output from earlier told us that the maximum heart rate was 165 bpm with an average of 142 bpm. Looking at the graph, an average of 142 bpm seems about right. It also looks like the maximum pulse value occurred at an elapsed time of just short of 50 minutes. We can check that guess more closely later.
What’s intriguing me now is what caused this pattern in the heart rate data.
What could have caused the values to go up and down like that? Is there a
correlation with other data fields? We know from earlier that there’s an
altitude field, so we can try plotting that along with the heart rate data
and see how (or if) they’re related.
Careful readers might have noticed something: how can you have a variation in altitude when you’re sitting on an indoor trainer? Well, Zwift simulates going up and downhill by changing the resistance in the smart trainer. The resistance is then correlated to a gradient and, given time and speed data, one can work out a virtual altitude gain or loss. Thus, for the data set we’re analysing here, altitude is a sensible parameter to consider. Even if you had no vertical motion whatsoever!
As I mentioned earlier, one of the things I like about Gnuplot is that one can plot two data sets with different y-axes on the same plot. Plotting heart rate and altitude on the same graph is one such use case.
To plot an extra data set on our graph, we need to set up another
Chart::Gnuplot::DataSet object, this time for the altitude data. Before
we can do that, we’ll have to extract the altitude data from the full
activity data set. Gnuplot also needs to know which data to plot on the
primary and secondary y-axes (i.e. on the left- and right-hand sides of the
graph). And we must remember to label our axes
properly. That’s a fair bit of work, so I’ve done
the hard
yakka for
ya. 😉
Here’s the updated plot_activity_data() code:
1sub plot_activity_data {
2 my @activity_data = @_;
3
4 # extract data to plot from full activity data
5 my @heart_rates = num_parts('heart_rate', @activity_data);
6 my @timestamps = map { $_->{'timestamp'} } @activity_data;
7 my @altitudes = num_parts('altitude', @activity_data);
8
9 # parse timestamp data
10 my $date_parser = DateTime::Format::Strptime->new(
11 pattern => "%Y-%m-%dT%H:%M:%SZ",
12 time_zone => 'UTC',
13 );
14
15 # get the epoch time for the first point in the time data
16 my $first_epoch_time = $date_parser->parse_datetime($timestamps[0])->epoch;
17
18 # convert timestamp data to elapsed minutes from start of activity
19 my @times = map {
20 my $dt = $date_parser->parse_datetime($_);
21 my $epoch_time = $dt->epoch;
22 my $elapsed_time = ($epoch_time - $first_epoch_time)/60;
23 $elapsed_time;
24 } @timestamps;
25
26 # determine date from timestamp data
27 my $dt = $date_parser->parse_datetime($timestamps[0]);
28 my $date = $dt->strftime("%Y-%m-%d");
29
30 # plot data
31 my $chart = Chart::Gnuplot->new(
32 output => "watopia-figure-8-heart-rate-and-altitude.png",
33 title => "Figure 8 in Watopia on $date: heart rate and altitude over time",
34 xlabel => "Elapsed time (min)",
35 ylabel => "Heart rate (bpm)",
36 terminal => "png size 1024, 768",
37 xtics => {
38 incr => 5,
39 },
40 y2label => 'Altitude (m)',
41 y2range => [-10, 70],
42 y2tics => {
43 incr => 10,
44 },
45 );
46
47 my $heart_rate_ds = Chart::Gnuplot::DataSet->new(
48 xdata => \@times,
49 ydata => \@heart_rates,
50 style => "lines",
51 );
52
53 my $altitude_ds = Chart::Gnuplot::DataSet->new(
54 xdata => \@times,
55 ydata => \@altitudes,
56 style => "boxes",
57 axes => "x1y2",
58 );
59
60 $chart->plot2d($altitude_ds, $heart_rate_ds);
61}
Line 7 extracts the altitude data from the full activity data. This code
also strips the unit information from the altitude data so that we only have
the numerical part, which is what Gnuplot needs. We store the altitude data
in the @altitudes array. This we use later to create a
Chart::Gnuplot::DataSet object on lines 53-58. An important line to note
here is the axes setting on line 57; it tells Gnuplot to use the secondary
y-axis on the right-hand side for this data set. I’ve chosen to use the
boxes style for the altitude data (line 56) so that the output looks a bit
like the hills and valleys that it represents.
To make the time data a bit easier to read and analyse, I’ve set the increment for the ticks on the x-axis to 5 (lines 37-39). This way it’ll be easier to refer to specific changes in altitude and heart rate data.
The settings for the secondary y-axis use the same names as for the primary
y-axis, with the exception that the string y2 replaces y. For instance,
to set the axis label for the secondary y-axis, we specify the y2label
value, as in line 40 above.
I’ve set the range on the secondary y-axis explicitly (line 41) because the output looks better than what the automatic range was able to make in this case. Similarly, I’ve set the increment on the secondary y-axis ticks (lines 42-44) because the automatic output wasn’t as good as what I wanted.
I’ve also renamed the variable for the heart rate data set on line 47 to be
more descriptive; the name $data_set was much too generic.
We specify the altitude data set first in the call to plot2d() (line 60)
because we want the heart rate data plotted “on top” of the altitude data.
Had we used $heart_rate_ds first in this call, the altitude data would
have obscured part of the heart rate data.
Running our script in the now familiar way
$ perl geo-fit-plot-data.pl
gives this plot
Cool! Now it’s a bit clearer why the heart rate evolved the way it did.
At the beginning of the graph (in the first ~10 minutes) it looks like I was getting warmed up and my pulse was finding a kind of base level (~130 bpm). Then things started going uphill at about the 10-minute mark and my pulse also kept going upwards. This makes sense because I was working harder. Between about 13 minutes and 19 minutes came the first hill climb on the route and here I was riding even harder. The effort is reflected in the heart rate data which rose to around 160 bpm at the top of the hill. That explains why the heart rate went up from the beginning to roughly the 18-minute mark.
Looking back over the Zwift data for that particular ride, it seems that I took the KOM8 for that climb at that time, so no wonder my pulse was high!9 Note that this wasn’t a special record or anything like that; it was a short-term live result10 and someone else took the jersey with a faster time not long after I’d done my best time up that climb.
It was all downhill shortly after the hill climb, which also explains why the heart rate went down straight afterwards. We also see similar behaviour on the second hill climb (from about 37 minutes to 42 minutes). Although my pulse rose throughout the hill climb, it didn’t rise as high this time. This indicates that I was getting tired and wasn’t able to put as much effort in.
Just in case you’re wondering how the altitude can go negative,11 part of the route goes through “underwater tunnels”. This highlights the flexibility of the virtual worlds within Zwift: the designers have enormous room to let their imaginations run wild. There are all kinds of fun things to discover along the various routes and many that don’t exist in the Real World™. Along with the underwater tunnels (where it’s like riding through a giant aquarium, with sunken shipwrecks, fish, and whales), there is a wild west style town complete with a steam train from that era chugging past. There are also Mayan ruins with llamas (or maybe alpacas?) wandering around and even a section with dinosaurs grazing at the side of the road.
Here’s what it looks like riding through an underwater tunnel:
I think that’s pretty cool.
At the end of the ride (at ~53 minutes) my pulse dropped sharply. Since this was the warm-down phase of the ride, this also makes sense.
Power to the people!
There are two peaks in the heart rate data that don’t correlate with altitude (one at ~25 minutes and another at ~48 minutes). The altitude change at these locations would suggest that things are fairly flat. What’s going on there?
One other parameter that we could consider for correlations is power output. Going uphill requires more power than riding on the flat, so we’d expect to see higher power values (and therefore higher heart rates) when climbing. If flat roads require less power, what’s causing the peaks in the pulse? Maybe there’s another puzzle hiding in the data.
Let’s combine the heart rate data with power output and see what other relationships we can discover. To do this we need to extract power output data instead of altitude data. Then we need to change the secondary y-axis data set and configuration to produce a nice plot of power output. Making these changes gives this code:
1sub plot_activity_data {
2 my @activity_data = @_;
3
4 # extract data to plot from full activity data
5 my @heart_rates = num_parts('heart_rate', @activity_data);
6 my @timestamps = map { $_->{'timestamp'} } @activity_data;
7 my @powers = num_parts('power', @activity_data);
8
9 # parse timestamp data
10 my $date_parser = DateTime::Format::Strptime->new(
11 pattern => "%Y-%m-%dT%H:%M:%SZ",
12 time_zone => 'UTC',
13 );
14
15 # get the epoch time for the first point in the time data
16 my $first_epoch_time = $date_parser->parse_datetime($timestamps[0])->epoch;
17
18 # convert timestamp data to elapsed minutes from start of activity
19 my @times = map {
20 my $dt = $date_parser->parse_datetime($_);
21 my $epoch_time = $dt->epoch;
22 my $elapsed_time = ($epoch_time - $first_epoch_time)/60;
23 $elapsed_time;
24 } @timestamps;
25
26 # determine date from timestamp data
27 my $dt = $date_parser->parse_datetime($timestamps[0]);
28 my $date = $dt->strftime("%Y-%m-%d");
29
30 # plot data
31 my $chart = Chart::Gnuplot->new(
32 output => "watopia-figure-8-heart-rate-and-power.png",
33 title => "Figure 8 in Watopia on $date: heart rate and power over time",
34 xlabel => "Elapsed time (min)",
35 ylabel => "Heart rate (bpm)",
36 terminal => "png size 1024, 768",
37 xtics => {
38 incr => 5,
39 },
40 ytics => {
41 mirror => "off",
42 },
43 y2label => 'Power (W)',
44 y2range => [0, 1100],
45 y2tics => {
46 incr => 100,
47 },
48 );
49
50 my $heart_rate_ds = Chart::Gnuplot::DataSet->new(
51 xdata => \@times,
52 ydata => \@heart_rates,
53 style => "lines",
54 );
55
56 my $power_ds = Chart::Gnuplot::DataSet->new(
57 xdata => \@times,
58 ydata => \@powers,
59 style => "lines",
60 axes => "x1y2",
61 );
62
63 $chart->plot2d($power_ds, $heart_rate_ds);
64}
On line 7, I swapped out the altitude data extraction code with power output. Then, I updated the output filename (line 32) and plot title (line 33) to highlight that we’re now plotting heart rate and power data.
The mirror option to the ytics setting (lines 40-42) isn’t an obvious
change. Its purpose is to stop the ticks from the primary y-axis from being
mirrored to the secondary y-axis (on the right-hand side). We want to stop
these mirrored ticks from appearing because they’ll clash with the secondary
y-axis tick marks. The reason we didn’t need this before is that all the
y-axis ticks happened to line up and the issue wasn’t obvious until now.
I’ve updated the secondary axis label setting to mention power (line 43).
Also, I’ve set the range to match the data we’re plotting (line 44) and to
space out the data nicely via the incr option to the y2tics setting
(lines 45-47). It seemed more appropriate to use lines to plot power output
as opposed to the bars we used for the altitude data, hence the change to
the style option on line 59.
As we did when plotting altitude, we pass the power data set ($power_ds)
to the plot2d() call before $heart_rate_ds (line 63).
Running the script again
$ perl geo-fit-plot-data.pl
produces this plot:
This plot shows the correlation between heart rate and power output that we expected for the first hill climb. The power output increases steadily from the 3-minute mark up to about the 18-minute mark. After that, it dropped suddenly once I’d reached the top of the climb. This makes sense: I’d just done a personal best up that climb and needed a bit of respite!
However, now we can see clearly what caused the spikes in heart rate at 25 minutes and 48 minutes: there are two large spikes in power output. The first spike maxes out at 1023 W;12 what value the other peak has, it’s hard to tell. We’ll try to work out what that value is later. These spikes in power result from sprints. In Zwift, not only can one try to go up hills as fast as possible, but flatter sections have sprints where one also tries to go as fast as possible, albeit for shorter distances (say 200m or 500m).
Great! We’ve worked out another puzzle in the data!
A quick comparison
Zwift produces what they call timelines of a given ride, which is much the same as what we’ve been plotting here. For instance, for the FIT file we’ve been looking at, this is the timeline graph:
Zwift plots several datasets on this graph that have very different value ranges. The plot above shows power output, cadence, heart rate, and altitude data all on one graph! A lot is going on here and because of the different data values and ranges, Zwift doesn’t display values on the y-axes. Their solution is to show all four values at a given time point when the user hovers their mouse over the graph. This solution only works within a web browser and needs lots of JavaScript to work, hence this is something I like to avoid. That (and familiarity) is largely the reason why I prefer PNG output for my graphs.
If you take a close look at the timeline graph, you’ll notice that the maximum power is given as 937 W and not 1023 W, which we worked out from the FIT file data. I don’t know what’s going on here, as the same graph in the Zwift Companion App shows the 1023 W that we got. The graph above is a screenshot from the web application in a browser on my laptop and, at least theoretically, it’s supposed to display the same data. I’ve noticed a few inconsistencies between the web browser view and that from the Zwift Companion App, so maybe this discrepancy is one bug that still needs shaking out.
A dialogue with data
Y’know what’d also be cool beyond plotting this data? Playing around with it interactively.
That’s also possible with Perl, but it’s another story.
-
I’ve been using Gnuplot since the late 90’s. Back then, it was the only freely available plotting software which handled time data well. ↩︎
-
By default, Gnuplot will generate Postscript output. ↩︎
-
One can interpret the word “terminal” as a kind of “screen” or “canvas” that the plotting library draws its output on. ↩︎
-
I’ve later found out that they haven’t heard anything, so that’s good! ↩︎
-
I live in Germany, so this is the relevant time zone for me. ↩︎
-
All dates are the same and displaying them would be redundant, hence we omit the date information. ↩︎
-
All elements in the array have the same date, so using the first one does the job. ↩︎
-
KOM stands for “king of the mountains”. ↩︎
-
Yes, I am stoked that I managed to take that jersey! Even if it was only for a short time. ↩︎
-
A live result that makes it onto a leaderboard is valid only for one hour. ↩︎
-
Around the 5-minute mark and again shortly before the 35-minute mark. ↩︎
-
One thing that this value implies is that I could power a small bar heater for one second. But not for very much longer! ↩︎
FIT files record the activities of people using devices such as sports watches and bike head units. Platforms such as Strava and Zwift understand this now quasi-standard format. So does Perl! Here I discuss how to parse FIT files and calculate some basic statistics from the extracted data.
Gotta love that data
I love data. Geographical data, time series data, simulation data, whatever. Whenever I get my hands on a new dataset, I like to have a look at it and visualise it. This way I can get a feel for what’s available and to see what kind of information I can extract from the long lists of numbers. I guess this comes with having worked in science for so long: there’s always some interesting dataset to look at and analyse and try to understand.
I began collecting lots of data recently when I started riding my bike more. Bike head units can save all sorts of information about one’s ride. There are standard parameters such as time, position, altitude, temperature, and speed. If you have extra sensors then you can also measure power output, heart rate, and cadence. This is a wealth of information just waiting to be played with!
I’ve also recently started using Zwift1 and there I can get even more data than on my road bike. Now I can get power and cadence data along with the rest of the various aspects of a normal training ride.
My head unit is from Garmin2 and thus saves ride data in their standard FIT format. Zwift also allows you to save ride data in FIT format, so you don’t have to deal with multiple formats when reading and analysing ride data. FIT files can also be uploaded to Strava3 where you can track all the riding you’re doing in one location.
But what if you don’t want to use an online service to look at your ride data? What if you want to do this yourself, using your own tools? That’s what I’m going to talk about here: reading ride data from FIT files and analysing the resulting information.
Because I like Perl, I wondered if there are any modules available to read
FIT files. It turns out that there are two:
Geo::FIT and
Parser::FIT. I chose to use
Geo::FIT because Parser::FIT is still in alpha status. Also, Geo::FIT
is quite mature with its last release in 2024, so it is still up-to-date.
The FIT format
The Garmin developer site explains all the gory details of the FIT format. The developer docs give a good high-level overview of what the format is for:
The Flexible and Interoperable Data Transfer (FIT) protocol is a format designed specifically for the storing and sharing of data that originates from sport, fitness and health devices. It is specifically designed to be compact, interoperable and extensible.
A FIT file has a well-defined structure and contains a series of records of different types. There are definition messages which describe the data appearing in the file. There are also data messages which contain the data fields storing a ride’s various parameters. Header fields contain such things as CRC information which one can use to check a file’s integrity.
Getting the prerequisites ready
As noted above, to extract the data, I’m going to use the
Geo::FIT module. It’s based on
the Garmin::Fit module originally by Kiyokazu
Suto and later
expanded upon by Matjaz Rihtar.
Unfortunately, neither was ever released to
CPAN. The latest releases
of the Garmin::FIT code (either version) were in 2017. In contrast,
Geo::FIT’s most recent release is from 2024-07-13 and it’s available on
CPAN, making it easy to install. It’s great to see that someone has taken
on the mantle of maintaining this codebase!
To install Geo::FIT, we’ll use cpanm:
$ cpanm Geo::FIT
Now we’re ready to start parsing FIT files and extracting their data.
Extracting data: a simple example
As mentioned earlier, FIT files store event data in data messages. Each event has various fields, depending upon the kind of device (e.g. watch or head unit) used to record the activity. More fields are possible if other peripherals are attached to the main device (e.g. power meter or heart rate monitor). We wish to extract all available event data.
To extract (and if we want to, process) the event data, Geo::FIT requires
that we define a callback function and register it. Geo::FIT calls this
function each time it detects a data message, allowing us to process the
file in small bites as a stream of data rather than one giant blob.
Simple beginnings
A simple example should explain the process. I’m going to adapt the example
mentioned in the module’s
synopsis. Here’s the code
(which I’ve put into a file called geo-fit-basic-data-extraction.pl):
1use strict;
2use warnings;
3
4use Geo::FIT;
5
6my $fit = Geo::FIT->new();
7$fit->file( "2025-05-08-07-58-33.fit" );
8$fit->open or die $fit->error;
9
10my $record_callback = sub {
11 my ($self, $descriptor, $values) = @_;
12 my $time= $self->field_value( 'timestamp', $descriptor, $values );
13 my $lat = $self->field_value( 'position_lat', $descriptor, $values );
14 my $lon = $self->field_value( 'position_long', $descriptor, $values );
15 print "Time was: ", join("\t", $time, $lat, $lon), "\n"
16};
17
18$fit->data_message_callback_by_name('record', $record_callback ) or die $fit->error;
19
20my @header_things = $fit->fetch_header;
21
221 while ( $fit->fetch );
23
24$fit->close;
The only changes I’ve made from the original example code have been to
include the strict and warnings strictures on lines 1 and 2, and to
replace the $fname variable with the name of a FIT file exported from one
of my recent Zwift rides (line 7).
After having imported the module (line 4), we instantiate a Geo::FIT
object (line 6). We then tell Geo::FIT the name of the file to process by
calling the file() method on line 7. This method returns the name of the
file if it’s called without an argument. We open the file on line 8 and
barf with an error if anything went wrong.
Lines 10-16 define the callback function, which must accept the given
argument list. Within the callback, the field_value() method extracts the
value with the given field name from the FIT data message (lines 12-14).
I’ll talk about how to find out what field names are available later. In
this example, we extract the timestamp as well as the latitude and longitude
of where the event happened. Considering that Garmin is a company that has
focused on GPS sensors, it makes sense that such data is the minimum we
would expect to find in a FIT file.
On line 18 we register the callback with the Geo::FIT object. We tell it
that the callback should be run whenever Geo::FIT sees a data message with
the name record4. Again, the code barfs with an
error if anything goes wrong.
The next line (line 20) looks innocuous but is actually necessary. The
fetch_header() method must be called before we can fetch any data from
the FIT file. Calling this method also returns header information, part of
which we can use to check the file integrity. This is something we might
want to use in a robust application as opposed to a simple script such as
that here.
The main action takes place on line 22. We read each data message from the
FIT file and–if it’s a data message with the name record–process it with
our callback.
At the end (line 24), we’re good little developers and close the file.
Running this code, you’ll see lots of output whiz past. It’ll look something like this:
$ perl geo-fit-basic-data-extraction.pl
<snip>
Time was: 2025-05-08T06:53:10Z -11.6379448 deg 166.9560685 deg
Time was: 2025-05-08T06:53:11Z -11.6379450 deg 166.9560904 deg
Time was: 2025-05-08T06:53:12Z -11.6379451 deg 166.9561073 deg
Time was: 2025-05-08T06:53:13Z -11.6379452 deg 166.9561185 deg
Time was: 2025-05-08T06:53:14Z -11.6379452 deg 166.9561232 deg
Time was: 2025-05-08T06:53:15Z -11.6379452 deg 166.9561233 deg
Time was: 2025-05-08T06:53:16Z -11.6379452 deg 166.9561233 deg
Time was: 2025-05-08T06:53:17Z -11.6379452 deg 166.9561233 deg
This tells us that, at the end of my ride on Zwift, I was at a position of roughly 11°S, 167°E shortly before 07:00 UTC on the 8th of May 2025.5 Because Zwift has virtual worlds, this position tells little of my actual physical location at the time. Hint: my spare room (where I was riding my indoor trainer) isn’t located at this position. 😉
Getting a feel for the fields
We want to get serious, though, and not only extract position and timestamp
data. There’s more in there to discover! So how do we find out what fields
are available? For this task, we need to use the fields_list() method.
To extract the list of available field names, I wrote the following script,
which I called geo-fit-find-field-names.pl:
1use strict;
2use warnings;
3
4use Geo::FIT;
5use Scalar::Util qw(reftype);
6
7my $fit = Geo::FIT->new();
8$fit->file( "2025-05-08-07-58-33.fit" );
9$fit->open or die $fit->error;
10
11my $record_callback = sub {
12 my ($self, $descriptor, $values) = @_;
13 my @all_field_names = $self->fields_list($descriptor);
14
15 return \@all_field_names;
16};
17
18$fit->data_message_callback_by_name('record', $record_callback ) or die $fit->error;
19
20my @header_things = $fit->fetch_header;
21
22my $found_field_names = 0;
23do {
24 my $field_names = $fit->fetch;
25 my $reftype = reftype $field_names;
26 if (defined $reftype && $reftype eq 'ARRAY') {
27 print "Number of field names found: ", scalar @{$field_names}, "\n";
28
29 while (my @next_field_names = splice @{$field_names}, 0, 5) {
30 my $joined_field_names = join ", ", @next_field_names;
31 print $joined_field_names, "\n";
32 }
33 $found_field_names = 1;
34 }
35} while ( !$found_field_names );
36
37$fit->close;
This script extracts and prints the field names from the first data message
it finds. Here, I’ve changed the callback (lines 11-16) to only return the
list of all available field names by calling the fields_list() method. We
return the list of field names as an array reference (line 15). While this
particular change to the callback (in comparison to
geo-fit-basic-data-extraction.pl, above) will do the job, it’s not very
user-friendly. It will print the field names for all data messages in the
FIT file, which is a lot. The list of all available field names would be
repeated thousands of times! So, I changed the while loop to a do-while
loop (lines 23-35), exiting as soon as the callback finds a data message
containing field names.
To actually grab the field name data, I had to get a bit tricky. This is
because fetch() returns different values depending upon whether the
callback was called. For instance, when the callback isn’t called, the
return value is 1 on success or undef. If the callback function is
called, fetch() returns the callback’s return value, which in our case is
the array reference to the list of field names. Hence, I’ve assigned the
return value to a variable, $field_names (line 24). To ensure that we’re
only processing data returned when the callback is run, we check that
$field_names is defined and has a reference type of ARRAY (line 26).
This we do with the help of the reftype function from Scalar::Util (line
25).
It turns out that there are 49 field names available (line 27). To format
the output more nicely I spliced the array, extracting five elements at a
time (line 29) and printing them as a comma-separated string (lines 30 and
31). I adapted the while (splice) pattern from the example in the Perl
documentation for splice.
Note that I could have printed the field names from within the callback. It
doesn’t make much of a difference if we return data from the callback first
before processing it or doing the processing within the callback. In this
case, I chose to do the former.
Running the script gives the following output:
$ perl geo-fit-find-field-names.pl
Use of uninitialized value $emsg in string ne at /home/vagrant/perl5/perlbrew/perls/perl-5.38.3/lib/site_perl/5.38.3/Geo/FIT.pm line 7934.
Use of uninitialized value $emsg in string ne at /home/vagrant/perl5/perlbrew/perls/perl-5.38.3/lib/site_perl/5.38.3/Geo/FIT.pm line 7992.
Number of field names found: 49
timestamp, position_lat, position_long, distance, time_from_course
total_cycles, accumulated_power, enhanced_speed, enhanced_altitude, altitude
speed, power, grade, compressed_accumulated_power, vertical_speed
calories, vertical_oscillation, stance_time_percent, stance_time, ball_speed
cadence256, total_hemoglobin_conc, total_hemoglobin_conc_min, total_hemoglobin_conc_max, saturated_hemoglobin_percent
saturated_hemoglobin_percent_min, saturated_hemoglobin_percent_max, heart_rate, cadence, compressed_speed_distance
resistance, cycle_length, temperature, speed_1s, cycles
left_right_balance, gps_accuracy, activity_type, left_torque_effectiveness, right_torque_effectiveness
left_pedal_smoothness, right_pedal_smoothness, combined_pedal_smoothness, time128, stroke_type
zone, fractional_cadence, device_index, 1_6_target_power
Note that the uninitialized value warnings are from Geo::FIT.
Unfortunately, I don’t know what’s causing them. They appear whenever we
fetch data from the FIT file. From now on, I’ll omit these warnings from
program output in this article.
As you can see, there’s potentially a lot of information one can obtain
from FIT files. I say “potentially” here because not all these fields
contain valid data, as we’ll see soon. I was quite surprised at the level
of detail. For instance, there are various pedal smoothness values, stroke
type, and torque effectiveness parameters. Also, there’s haemoglobin
information,6 which I guess is something one can
collect given the appropriate peripheral device. What things like enhanced
speed and compressed accumulated power mean, I’ve got no idea. For me, the
interesting parameters are: timestamp, position_lat, position_long,
distance, altitude, speed, power, calories, heart_rate, and
cadence. We’ll get around to extracting and looking at these values soon.
Event data: a first impression
Let’s see what values are present in each of the fields. To do this, we’ll
change the callback to collect the values in a hash with the field names as
the hash keys. Then we’ll return the hash from the callback. Here’s the
script I came up with (I called it geo-fit-show-single-values.pl):
1use strict;
2use warnings;
3
4use Geo::FIT;
5use Scalar::Util qw(reftype);
6
7my $fit = Geo::FIT->new();
8$fit->file( "2025-05-08-07-58-33.fit" );
9$fit->open or die $fit->error;
10
11my $record_callback = sub {
12 my ($self, $descriptor, $values) = @_;
13 my @all_field_names = $self->fields_list($descriptor);
14
15 my %event_data;
16 for my $field_name (@all_field_names) {
17 my $field_value = $self->field_value($field_name, $descriptor, $values);
18 $event_data{$field_name} = $field_value;
19 }
20
21 return \%event_data;
22};
23
24$fit->data_message_callback_by_name('record', $record_callback ) or die $fit->error;
25
26my @header_things = $fit->fetch_header;
27
28my $found_event_data = 0;
29do {
30 my $event_data = $fit->fetch;
31 my $reftype = reftype $event_data;
32 if (defined $reftype && $reftype eq 'HASH' && defined %$event_data{'timestamp'}) {
33 for my $key ( sort keys %$event_data ) {
34 print "$key = ", $event_data->{$key}, "\n";
35 }
36 $found_event_data = 1;
37 }
38} while ( !$found_event_data );
39
40$fit->close;
The main changes here (in comparison to the previous script) involve collecting the data into a hash (lines 15-19) and later, after fetching the event data, printing it (lines 32-35).
To collect data from an individual event, we first find out what the
available fields are (line 13). Then we loop over each field name (line
16), extracting the values via the field_value() method (line 17). To
pass the data outside the callback, we store the value in the %event_data
hash using the field name as a key (line 18). Finally, we return the event
data as a hash ref (line 21).
When printing the key and value information, we again only want to print the
first event that we come across. Hence we use a do-while loop and exit as
soon as we’ve found appropriate event data (line 38).
Making sure that we’re only printing relevant event data is again a bit
tricky. Not only do we need to make sure that the callback has returned a
reference type, but we also need to check that it’s a hash. Plus, we have
an extra check to make sure that we’re getting time series data by looking
for the presence of the timestamp key (line 32). Without the timestamp
key check, we receive data messages unrelated to the ride activity, which we
obviously don’t want.
Running this new script gives this output:
$ perl geo-fit-show-single-values.pl
1_6_target_power = 0
accumulated_power = 4294967295
activity_type = 255
altitude = 4.6 m
ball_speed = 65535
cadence = 84 rpm
cadence256 = 65535
calories = 65535
combined_pedal_smoothness = 255
compressed_accumulated_power = 65535
compressed_speed_distance = 255
cycle_length = 255
cycles = 255
device_index = 255
distance = 0.56 m
enhanced_altitude = 4294967295
enhanced_speed = 4294967295
fractional_cadence = 255
gps_accuracy = 255
grade = 32767
heart_rate = 115 bpm
left_pedal_smoothness = 255
left_right_balance = 255
left_torque_effectiveness = 255
position_lat = -11.6387709 deg
position_long = 166.9487493 deg
power = 188 watts
resistance = 255
right_pedal_smoothness = 255
right_torque_effectiveness = 255
saturated_hemoglobin_percent = 65535
saturated_hemoglobin_percent_max = 65535
saturated_hemoglobin_percent_min = 65535
speed = 1.339 m/s
speed_1s = 255
stance_time = 65535
stance_time_percent = 65535
stroke_type = 255
temperature = 127
time128 = 255
time_from_course = 2147483647
timestamp = 2025-05-08T05:58:45Z
total_cycles = 4294967295
total_hemoglobin_conc = 65535
total_hemoglobin_conc_max = 65535
total_hemoglobin_conc_min = 65535
vertical_oscillation = 65535
vertical_speed = 32767
zone = 255
That’s quite a list!
What’s immediately obvious (at least, to me) is that many of the values look
like maximum integer range values. For instance, activity_type = 255
suggests that this value ranges from 0 to 255, implying that it’s an 8-bit
integer. Also, the numbers 65535 and 4294967295 are the maximum values of
16-bit and 32-bit integers, respectively. This “smells” of dummy values
being used to fill the available keys with something other than 0. Thus, I
get the feeling that we can ignore such values.
Further, most of the values that aren’t only an integer have units attached.
For instance, the speed is given as 1.339 m/s and the latitude coordinate
as -11.6387709 deg. Note the units associated with these values. The
only value without a unit–yet is still a sensible value–is timestamp.
This makes sense, as a timestamp doesn’t have a unit.
This is the next part of the puzzle to solve: we need to work out how to extract relevant event data and filter out anything containing a dummy value.
Focusing on what’s relevant
To filter out the dummy values and hence focus only on real event data, we
use the fact that real event data contains a string of letters denoting the
value’s unit. Thus, the event data we’re interested in has a value
containing numbers and letters. Fortunately, this is also the case for the
timestamp because it contains timezone information, denoted by the letter
Z, meaning UTC. In other words, we can solve our problem with a
regex.7
Another way of looking at the problem would be to realise that all the irrelevant data contains only numbers. Thus, if a data value contains a letter, we should select it. Either way, the easiest approach is to look for a letter by using a regex.
I’ve modified the script above to filter out the dummy event data and to
collect valid event data into an array for the entire
activity.8 Here’s what the code looks like now (I’ve
called the file geo-fit-full-data-extraction.pl):
1use strict;
2use warnings;
3
4use Geo::FIT;
5use Scalar::Util qw(reftype);
6
7my $fit = Geo::FIT->new();
8$fit->file( "2025-05-08-07-58-33.fit" );
9$fit->open or die $fit->error;
10
11my $record_callback = sub {
12 my ($self, $descriptor, $values) = @_;
13 my @all_field_names = $self->fields_list($descriptor);
14
15 my %event_data;
16 for my $field_name (@all_field_names) {
17 my $field_value = $self->field_value($field_name, $descriptor, $values);
18 if ($field_value =~ /[a-zA-Z]/) {
19 $event_data{$field_name} = $field_value;
20 }
21 }
22
23 return \%event_data;
24};
25
26$fit->data_message_callback_by_name('record', $record_callback ) or die $fit->error;
27
28my @header_things = $fit->fetch_header;
29
30my $event_data;
31my @activity_data;
32do {
33 $event_data = $fit->fetch;
34 my $reftype = reftype $event_data;
35 if (defined $reftype && $reftype eq 'HASH' && defined %$event_data{'timestamp'}) {
36 push @activity_data, $event_data;
37 }
38} while ( $event_data );
39
40$fit->close;
41
42print "Found ", scalar @activity_data, " entries in FIT file\n";
43my $available_fields = join ", ", sort keys %{$activity_data[0]};
44print "Available fields: $available_fields\n";
The primary difference here with respect to the previous script is the check
within the callback for a letter in the field value (line 18). If that’s
true, we store the field value in the %event_data hash under a key
corresponding to the field name (line 19).
Later, if we have a hash and it has a timestamp key, we push the
$event_data hash reference onto an array. This way we store all events
related to our activity (line 36). Also, instead of checking that we got
only one instance of event data, we’re now looping over all event data in
the FIT file, exiting the do-while loop if $event_data is a falsey
value.9 Note that $event_data has to be declared outside
the do block. Otherwise, it won’t be in scope for the while statement
and Perl will barf with a compile-time error. We also declare the
@activity_data array outside the do-while loop because we want to use it
later.
After processing all records in the FIT file, we display the number of data entries found (line 42) and show a list of the available (valid) fields (lines 43-44).
Running this script gives this output:10
$ perl geo-fit-full-data-extraction.pl
Found 3273 entries in FIT file
Available fields: altitude, cadence, distance, heart_rate, position_lat, position_long, power, speed, timestamp
Right now, things are fairly average
We now have the full dataset to play with! So what can we do with it? One thing that springs to mind is to calculate the maximum and average values of each data series.
Given the list of available fields, my instincts tell me that it’d be nice to know what the following parameters are:
- total distance
- max speed
- average speed
- max power
- average power
- max heart rate
- average heart rate
Let’s calculate them now.
Going the distance
Finding the total distance is very easy. Since this is a cumulative quantity, we only need to select the value in the final data point. Then we convert it to kilometres by dividing by 1000, because the distance data is in units of metres. I.e.:
my $total_distance_m = (split ' ', ${$activity_data[-1]}{'distance'})[0];
my $total_distance = $total_distance_m/1000;
print "Total distance: $total_distance km\n";
Note that since the distance field value also contains its unit, we have
to split on spaces and take the first element to extract the numerical part.
Maxing out
To get maximum values (e.g. for maximum speed), we use the max function
from List::Util:
1my @speeds = map { (split ' ', $_->{'speed'})[0] } @activity_data;
2my $maximum_speed = max @speeds;
3my $maximum_speed_km = $maximum_speed*3.6;
4print "Maximum speed: $maximum_speed m/s = $maximum_speed_km km/h\n";
Here, I’ve extracted all speed values from the activity data, selecting only the numerical part (line 1). I then found the maximum speed on line 2 (which is in m/s) and converted this into km/h (line 3), displaying both at the end.
An average amount of work
Getting average values is a bit more work because List::Util doesn’t
provide an arithmetic mean function, commonly known as an “average”. Thus,
we have to calculate this ourselves. It’s not much work, though. Here’s
the code for the average speed:
1my $average_speed = (sum @speeds) / (scalar @speeds);
2my $average_speed_km = sprintf("%0.2f", $average_speed*3.6);
3$average_speed = sprintf("%0.2f", $average_speed);
4print "Average speed: $average_speed m/s = $average_speed_km km/h\n";
In this code, I’ve used the sum function from List::Util to find the sum
of all speed values in the entry data (line 1). Dividing this value by the
length of the array (i.e. scalar @speeds) gives the average value.
Because this value will have lots of decimal places, I’ve used sprintf to
show only two decimal places (this is what the "%0.2f" format statement
does on line 3). Again, I’ve calculate the value in km/h (line 2) and
show the average speed in both m/s and km/h.
Calculating a ride’s statistics
Extending the code to calculate and display all parameters I mentioned above, we get this:
my $total_distance_m = (split ' ', ${$activity_data[-1]}{'distance'})[0];
my $total_distance = $total_distance_m/1000;
print "Total distance: $total_distance km\n";
my @speeds = map { (split ' ', $_->{'speed'})[0] } @activity_data;
my $maximum_speed = max @speeds;
my $maximum_speed_km = $maximum_speed*3.6;
print "Maximum speed: $maximum_speed m/s = $maximum_speed_km km/h\n";
my $average_speed = (sum @speeds) / (scalar @speeds);
my $average_speed_km = sprintf("%0.2f", $average_speed*3.6);
$average_speed = sprintf("%0.2f", $average_speed);
print "Average speed: $average_speed m/s = $average_speed_km km/h\n";
my @powers = map { (split ' ', $_->{'power'})[0] } @activity_data;
my $maximum_power = max @powers;
print "Maximum power: $maximum_power W\n";
my $average_power = (sum @powers) / (scalar @powers);
$average_power = sprintf("%0.2f", $average_power);
print "Average power: $average_power W\n";
my @heart_rates = map { (split ' ', $_->{'heart_rate'})[0] } @activity_data;
my $maximum_heart_rate = max @heart_rates;
print "Maximum heart rate: $maximum_heart_rate bpm\n";
my $average_heart_rate = (sum @heart_rates) / (scalar @heart_rates);
$average_heart_rate = sprintf("%0.2f", $average_heart_rate);
print "Average heart rate: $average_heart_rate bpm\n";
If you’re following along at home–and assuming that you’ve added this code
to the end of geo-fit-full-data-extraction.pl–when you run the file, you
should see output like this:
$ perl geo-fit-full-data-extraction.pl
Found 3273 entries in FIT file
Available fields: altitude, cadence, distance, heart_rate, position_lat,
position_long, power, speed, timestamp
Total distance: 31.10591 km
Maximum speed: 18.802 m/s = 67.6872 km/h
Average speed: 9.51 m/s = 34.23 km/h
Maximum power: 1023 W
Average power: 274.55 W
Maximum heart rate: 165 bpm
Average heart rate: 142.20 bpm
Nice! That gives us more of a feel for the data and what we can learn from it. We can also see that I was working fairly hard on this bike ride as seen from the average power and average heart rate data.
Not so fast!
One thing to highlight about these numbers, from my experience riding both indoors and outdoors, is that the average speed on Zwift is too high. Were I riding my bike outside on the road, I’d be more likely to have an average speed of ~25 km/h, not the 34 km/h shown here. I think this discrepancy comes from Zwift not accurately converting power output into speed within the game.11 I’m not sure where the discrepancy comes from. Perhaps I don’t go as hard when out on the road? Dunno.
From experience, I know that it’s easier to put in more effort over shorter periods. Thus, I’d expect the average speed to be a bit higher indoors when doing shorter sessions. Another factor is that when riding outside one has to contend with stopping at intersections and traffic lights etc. Stopping and starting brings down the average speed on outdoor rides. These considerations might explain part of the discrepancy, but I don’t think it explains it all.
Refactoring possibilities
There’s some duplication in the above code that I could remove. For
instance, the code for extracting the numerical part of a data entry’s value
should really be in its own function. I don’t need to map over a split
each time; those are just implementation details that should hide behind a
nicer interface. Also, the average value calculation would be better in its
own function.
A possible refactoring to reduce this duplication could look like this:
# extract and return the numerical parts of an array of FIT data values
sub num_parts {
my $field_name = shift;
my @activity_data = @_;
return map { (split ' ', $_->{$field_name})[0] } @activity_data;
}
# return the average of an array of numbers
sub avg {
my @array = @_;
return (sum @array) / (scalar @array);
}
which one would use like so:
my @speeds = num_parts('speed', @activity_data);
my $average_speed = avg(@speeds);
Looking into the future
Seeing numerical values of ride statistics is all well and good, but it’s much nicer to see a picture of the data. To do this, we need to plot it.
But that’s a story for another time.
-
Note that I’m not affiliated with Zwift. I use the platform for training, especially for short rides, when the weather’s bad and in the winter. ↩︎
-
Note that I’m not affiliated with Garmin. I own a Garmin Edge 530 head unit and find that it works well for my needs. ↩︎
-
Note that I’m not affiliated with Strava. I’ve found the platform to be useful for individual ride analysis and for collating a year’s worth of training. ↩︎
-
There are different kinds of data messages. We usually want
records as these messages contain event data from sporting activities. ↩︎ -
For those wondering: these coordinates would put me on the island of Teanu, which is part of the Santa Cruz Islands. This island group is north of Vanuatu and east of the Solomon Islands in the Pacific Ocean. ↩︎
-
I expected this field to be spelled ‘haemoglobin’ rather than hemoglobin. Oh well. ↩︎
-
Jeff Attwood wrote an interesting take on the use of regular expressions. ↩︎
-
Garmin calls a complete ride (or run, if you’re that way inclined) an “activity”. Hence I’m using their nomenclature here. ↩︎
-
Remember that
fetch()returnsundefon failure or EOF. ↩︎ -
Note that I’ve removed the
uninitialized valuewarnings from the script output. ↩︎ -
Even though Zwift is primarily a training platform, it is also a game. There are power-ups and other standard gaming features such as experience points (XP). Accumulating XP allows you to climb up a ladder of levels which then unlocks other features and in-game benefits. This is the first computer game I’ve ever played where strength and fitness in real life play a major role in the in-game success. ↩︎
Maintaining Perl (Tony Cook) April 2025
Perl Foundation NewsPublished by alh on Sunday 22 June 2025 17:38
Tony writes: ``` [Hours] [Activity] 2025/04/01 Tuesday 0.22 #23151 check CI results, fix minitest and re-push 1.77 #23160 try to decode how the NEED_ stuff works, try leont’s suggestion and test, push for CI 0.82 #22125 check smoke results, rebase and push 0.50 #21878 consider how to implement this
0.53 ppc #70 testing, comment
3.84
2025/04/02 Wednesday 0.23 #23075 rebase and squash some, push for CI 0.98 test-dist-modules threaded testing: check CI results, remove 5.8, clean up commits, push for CI 0.10 #23075 check CI results and apply to blead
0.28 test-dist-modules: check CI, open PR 23167
1.59
2025/04/03 Thursday 0.37 #23151 check CI results, open PR 23171 1.60 #17601 side-issue: check history, testing, find an unrelated problem, work on a fix, testing 0.20 #17601 side-issue: push fix for CI, comment and mark
#17601 closable
2.17
2025/04/07 Monday 0.15 #22120 follow-up 1.57 #23151 add suggested change, testing and push 0.62 #23172 review and comment 0.20 #23177 review, research and apply to blead 0.37 #17601 side-issue: check CI results, add perldelta, cleanup commit message, open PR 23178 0.60 #23022 clean up, add perldelta, push for CI
0.73 #22125 re-check, rebase, push for CI
4.24
2025/04/08 Tuesday 0.53 #17601 research, minor fix and comment 0.08 #22125 fix test failure 0.48 #17601 side-issue: testing, research and comment 0.55 #16608 reproduce, code review
1.62 #16608 try to work out a reasonable solution
3.26
2025/04/09 Wednesday 1.23 #17601 side issue: add a panic message, research and comment 2.40 #16608 research, try to reproduce some other cases, comment, work on fixes, tests, work class initfields similar bug 1.83 #16608 fix an issue with smartmatch fix, work on initfields fix, testing, perldelta, push for CI, smoke-me 0.33 #17601 test another build configuration, minor fix and push 0.28 #23151 testing
0.23 #17601 comment
6.30
2025/04/10 Thursday 0.32 #16608 fix a minor issue and re-push 0.13 #23165 review updates and approve 2.28 look into smoke test failures, ASAN detected leak from op/signatures, debugging, make #23187 2.28 op/signatures leak: debugging, work it out (I think), work
on a fix, testing, push for CI/smoke-me
5.01
2025/06/14 Saturday 3.45 #23022 re-check, minor re-work, testing, push
0.35 #23187 op/signatures leak: comment, some re-work
3.80
2025/04/15 Tuesday 1.15 #23187 consider re-work, minor fix, testing, perldelta, push for CI 0.70 document that TARG isn’t pristine and the implications, open #23196 0.60 #16608 check smoke results, debugging and fix, push for CI/smoke 1.13 #22125 clean up commit history, testing, perldelta, more
testing and push for CI/smoke
3.58
2025/04/16 Wednesday 0.23 #23196 edits as suggested and push 1.50 #23187 check CI results, investigate ASAN results, which appear unrelated, open PR 23203 0.67 #23201 review, research a lot, approve 0.20 #16608 check CI results, make PR 23204 0.63 #1674 review history and research, comment since I’m
confused
3.23
2025/04/22 Tuesday 0.17 #23207 review, research and approve 0.92 #23208 review, testing and comment 1.80 #23202 review, testing 0.67 #23202 more review, testing 0.37 #23202 more review, comments 0.25 #23208 research and comment
0.43 #23215 research
4.61
2025/04/23 Wednesday 0.30 #23202 review responses 0.80 #23172 review updates, approve 0.22 #1674 research 1.63 #1674 more research, minor change, testing, push for CI 0.45 #3965 testing 0.23 #3965 more testing, comment and mark “Closable?” 0.10 #1674 review CI results and make PR 23219
1.22 #4106 debugging, research and comment
4.95
2025/04/24 Thursday 0.22 #23216 review and approve 0.08 #23217 review and approve 0.08 #23220 review and approve 1.10 #23215 testing, look if we can eliminate the conditional from cSVOPx_sv() on threads (we can’t directly, the non- pad sv is used at compile-time), approve 0.35 #23208 review, research, comments 1.27 #4106 research 2.70 #4106 testing for potential bugs and misbehaviour, chainsaw for w32_fdpid and make it like everyone else,
testing and push for CI
5.80
2025/04/28 Monday 0.35 #20841 comment 2.38 #22374 minor fixes, testing, force push to update, comments 0.13 #23226 review and approve 0.70 #23227 review, research, check build logs and comment
0.45 #23228 review, testing and comments
4.01
2025/04/29 Tuesday 0.42 #23228 check updates and approve 0.63 #23227 testing and comment 1.07 #23225 start review
1.23 #23225 more review
3.35
2025/04/30 Wednesday 1.28 #23227 review, testing, research and approve with comment 0.68 #4106 check results, look for existing tests that might test this, testing 2.23 #4106 review history, work on a new test, testing, push for CI 0.83 #23232 review docs, open Dual-Life/experimental#22 which
adjusts the version range and links to the docs
5.02
Which I calculate is 64.76 hours.
Approximately 33 tickets were reviewed or worked on, and 2 patches were applied. ```
<h3 class='likesectionHead' id='the-day-we-decompress'><a id='x1-1000'></a>The Day We Decompress</h3>
RabbitFarm PerlPublished on Sunday 22 June 2025 16:45
The examples used here are from the weekly challenge problem statement and demonstrate the working solution.
Part 1: Day of the Year
You are given a date in the format YYYY-MM-DD. Write a script to find day number of the year that the given date represent.
The core of the solution is contained in a main loop. The resulting code can be contained in a single file.
The answer is arrived at via a fairly straightforward calculation.
-
sub day_of_year {
my ($date) = @_;
my $day_of_year = 0;
my ($year, $month, $day) = split /-/, $date;
my @days_in_month = (31, $february_days, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31);
$day_of_year += $days_in_month[$_] for (0 .. $month - 2);
$day_of_year += $day;
return $day_of_year;
}
◇
Let’s break the logic for computing a leap year into it’s own section. A leap year occurs every 4 years, except for years that are divisible by 100, unless they are also divisible by 400.
Just to make sure things work as expected we’ll define a few short tests. The double chop is just a lazy way to make sure there aren’t any trailing commas in the output.
-
MAIN:{
say day_of_year q/2025-02-02/;
say day_of_year q/2025-04-10/;
say day_of_year q/2025-09-07/;
}
◇
-
Fragment referenced in 1.
Sample Run
$ perl perl/ch-1.pl 33 100 250
Part 2: Decompressed List
You are given an array of positive integers having even elements. Write a script to to return the decompress list. To decompress, pick adjacent pair (i, j) and replace it with j, i times.
For fun let’s use recursion!
Sometimes when I write a recursive subroutine in Perl I use a reference variable to set the return value. Other times I just use an ordinary return. In some cases, for convenience, I’ll do this with two subroutines. One of these is a wrapper which calls the main recursion.
For this problem I’ll do something a little different. I’ll have one subroutine and for each recursive call I’ll add in an array reference to hold the accumulating return value.
Note that we take advantage of Perl’s automatic list flattening when pushing to the array reference holding the new list we are building.
-
sub decompress_list{
my $r = shift @_;
if(!ref($r) || ref($r) ne q/ARRAY/){
unshift @_, $r;
$r = [];
}
unless(@_ == 0){
my $i = shift @_;
my $j = shift @_;
push @{$r}, ($j) x $i;
decompress_list($r, @_);
}
else{
return @{$r};
}
}
◇
-
Fragment referenced in 5.
The main section is just some basic tests.
-
MAIN:{
say join q/, /, decompress_list 1, 3, 2, 4;
say join q/, /, decompress_list 1, 1, 2, 2;
say join q/, /, decompress_list 3, 1, 3, 2;
}
◇
-
Fragment referenced in 5.
Sample Run
$ perl perl/ch-2.pl 3, 4, 4 1, 2, 2 1, 1, 1, 2, 2, 2
References
(dliii) 8 great CPAN modules released last week
NiceperlPublished by prz on Saturday 21 June 2025 22:13
-
App::Netdisco - An open source web-based network management tool.
- Version: 2.086002 on 2025-06-18, with 17 votes
- Previous CPAN version: 2.086001 was 14 days before
- Author: OLIVER
-
Cache::FastMmap - Uses an mmap'ed file to act as a shared memory interprocess cache
- Version: 1.60 on 2025-06-17, with 25 votes
- Previous CPAN version: 1.59 was 14 days before
- Author: ROBM
-
Imager - Perl extension for Generating 24 bit Images
- Version: 1.028 on 2025-06-16, with 68 votes
- Previous CPAN version: 1.027 was 3 months, 14 days before
- Author: TONYC
-
IO::Socket::SSL - Nearly transparent SSL encapsulation for IO::Socket::INET.
- Version: 2.094 on 2025-06-18, with 49 votes
- Previous CPAN version: 2.091 was 7 days before
- Author: SULLR
-
Perl::Tidy - indent and reformat perl scripts
- Version: 20250616 on 2025-06-15, with 143 votes
- Previous CPAN version: 20250311 was 3 months, 4 days before
- Author: SHANCOCK
-
perlfaq - Frequently asked questions about Perl
- Version: 5.20250619 on 2025-06-19, with 13 votes
- Previous CPAN version: 5.20240218 was 1 year, 4 months, 1 day before
- Author: ETHER
-
Specio - Type constraints and coercions for Perl
- Version: 0.51 on 2025-06-19, with 12 votes
- Previous CPAN version: 0.50 was 4 months before
- Author: DROLSKY
-
SPVM - The SPVM Language
- Version: 0.990071 on 2025-06-18, with 36 votes
- Previous CPAN version: 0.990067 was 5 days before
- Author: KIMOTO